Mình đã có 1 bài hướng dẫn các bạn tạo Connector Source CDC từ read data từ 1 database và 1 collection thuộc 1 Mongodb và write vào topic.
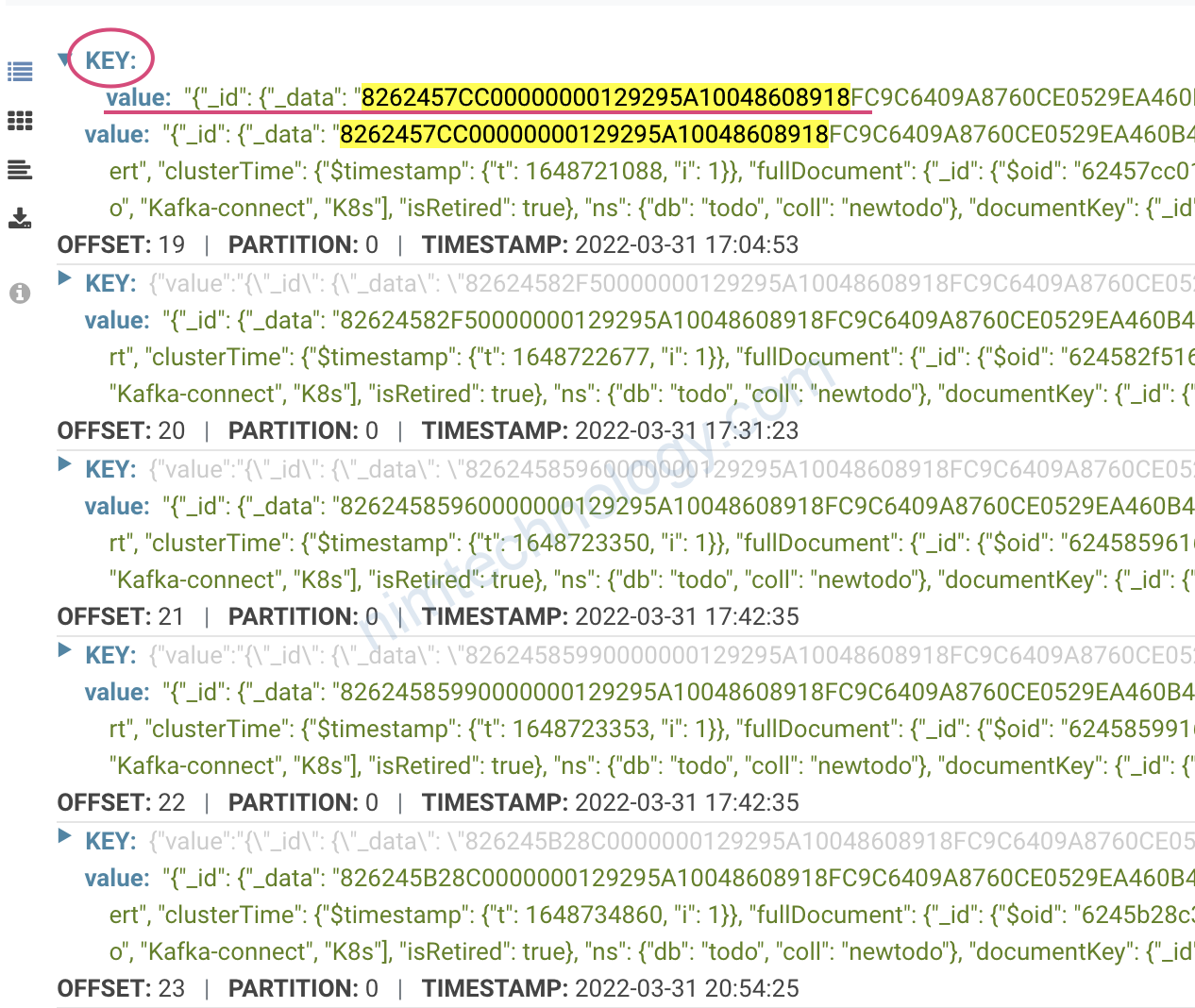
Ta để ý value của key sẽ thay đổi liên tục.
1st: Create Document A –(read data change)–> Kafka-connect –(write topic)–> Kafka –> 1 message có key: 1111 (partition 1)
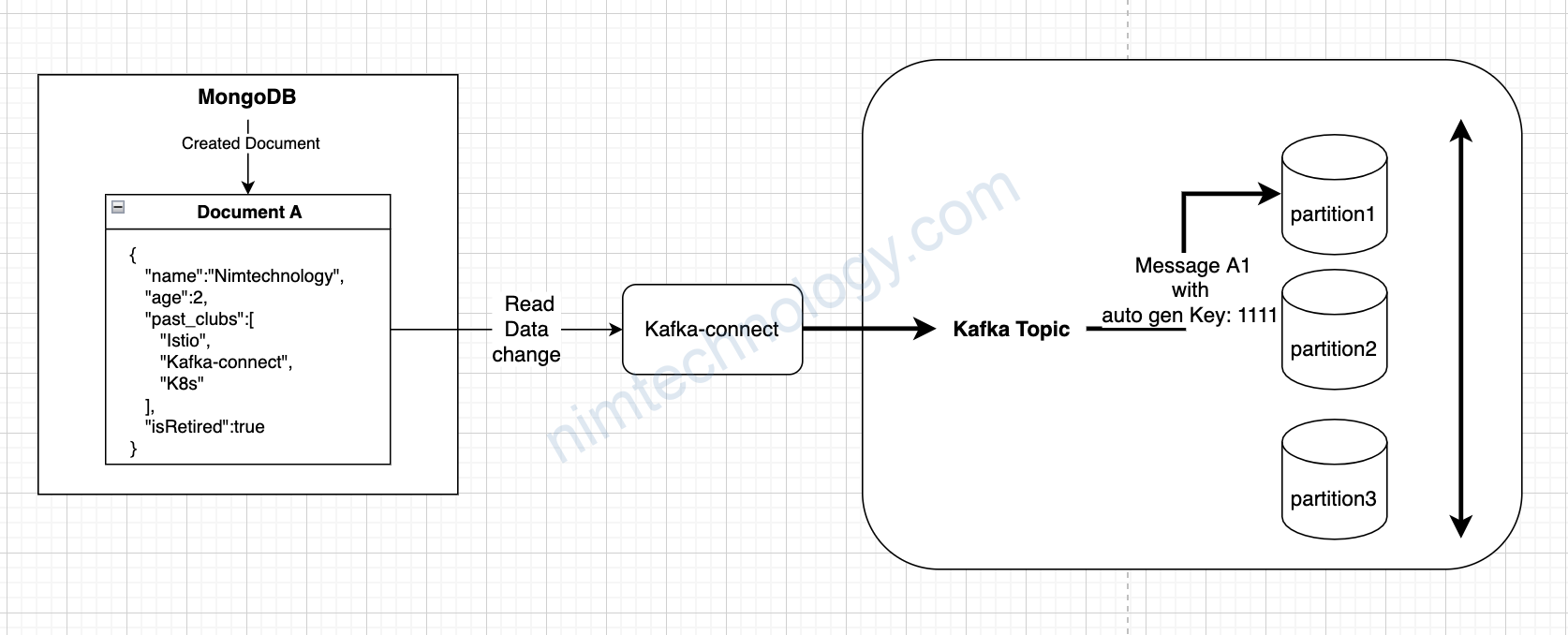
2rd: Edit Document A –(read data change)–> Kafka-connect –(write topic)–> Kafka –> 1 message có key: 1211 (partition 2)

Vậy làm sao để khi bạn tạo hoặc sửa Document A —> kafka-connect chỉ sinh ra 1 key duy nhất (key giống với lần create đầu tiên)
==> tất cả các message liên quan đến Document A đều đi vô 1 partition.

1) using “output.schema.key”
Bạn sẽ cần sử dụng:
MongoSourceConnector
Version: 1.7.0 | Author: Mongodb team
Trong config cần có cái này:
output.schema.key={"type":"record","name":"id","fields":[{"name":"documentKey._id","type":"string"}]}
output.format.key=schemaDưới đây là việc thử change config và view lại data trong topic!
connector.class=com.mongodb.kafka.connect.MongoSourceConnector
tasks.max=1
batch.size=0
change.stream.full.document=updateLookup
collection=newtodo
database=todo
topic.prefix=mongouat
poll.await.time.ms=5000
connection.uri=mongodb://192.168.101.27:27017/?replicaSet=rs0
name=source.mongo_connector.todo.v1
value.converter=org.apache.kafka.connect.storage.StringConverter
key.converter=org.apache.kafka.connect.storage.StringConverter
poll.max.batch.size=1000
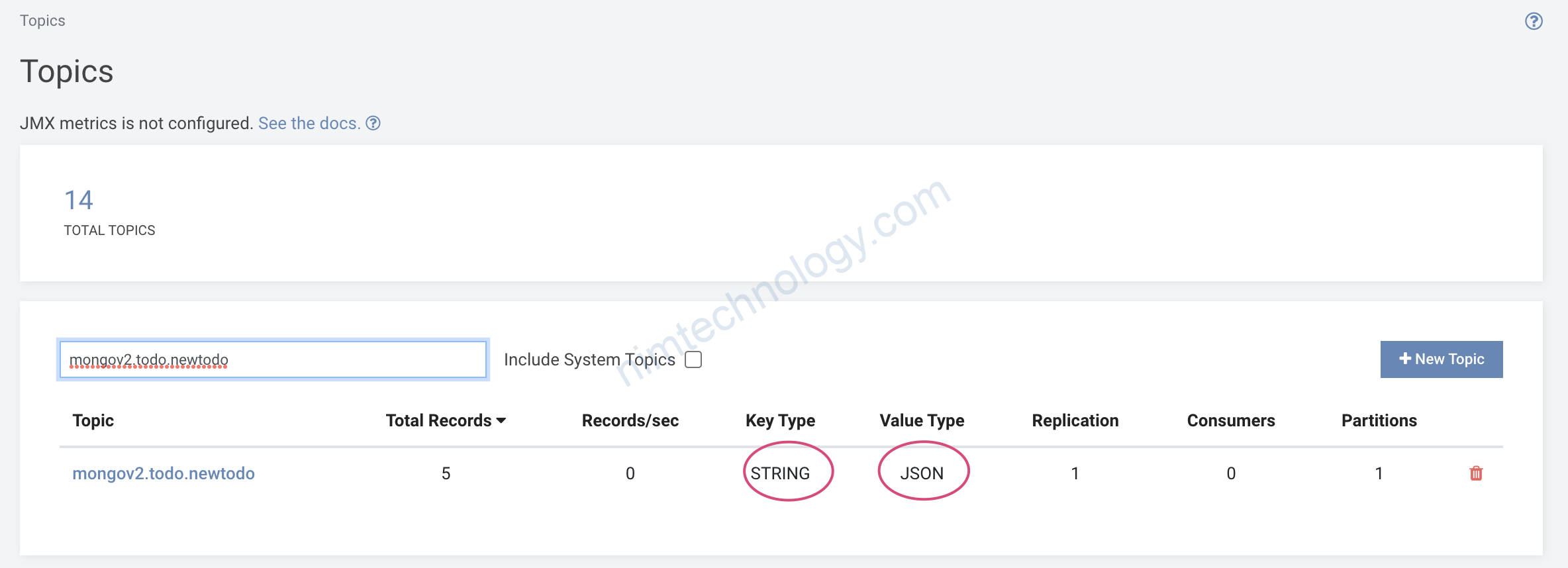
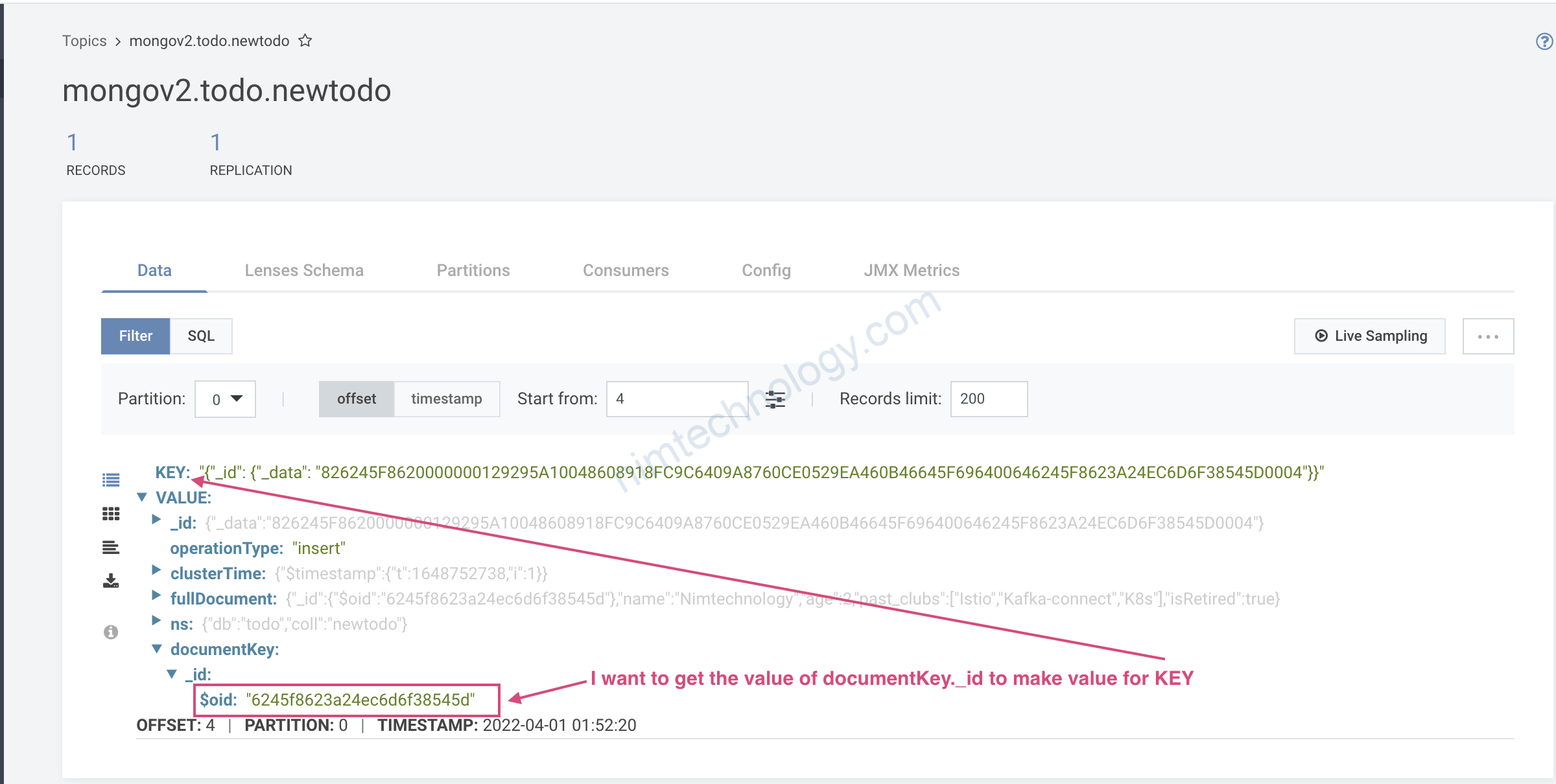
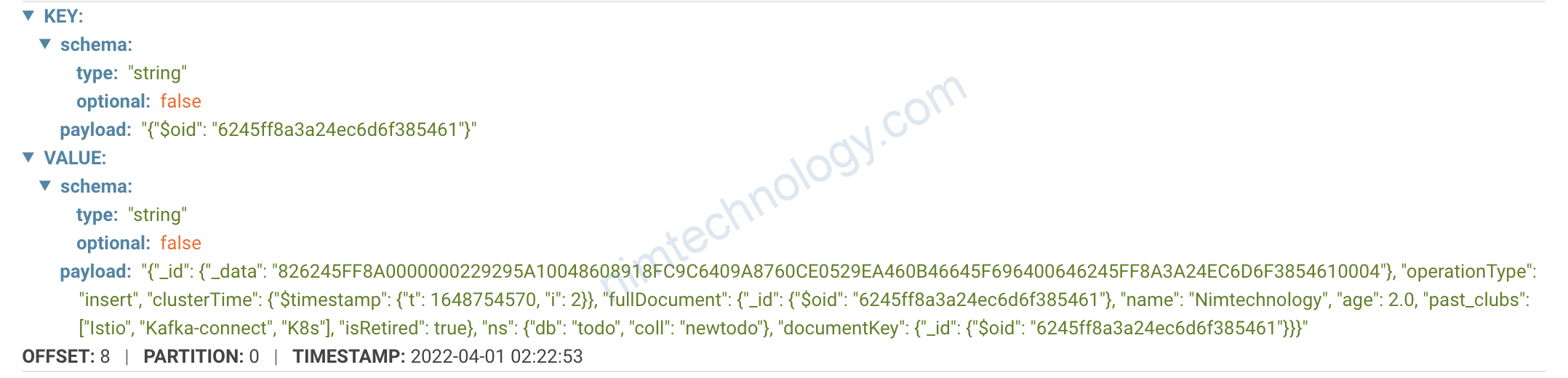
Mình muốn lấy giá trị của documentKey._id để làm value của KEY schema
có thể bạn sẽ thắc mắc sao mình ko lấy là documentKey._id.$oid
nếu dụng như trên thì nó lỗi
https://jira.mongodb.org/browse/KAFKA-162
bạn có thêm tham khảo links trên nghe đồn là hết lỗi.
connector.class=com.mongodb.kafka.connect.MongoSourceConnector
tasks.max=1
batch.size=0
change.stream.full.document=updateLookup
collection=newtodo
output.schema.key={"type":"record","name":"id","fields":[{"name":"documentKey._id","type":"string"}]}
output.format.key=schema
database=todo
topic.prefix=mongov2
poll.await.time.ms=5000
connection.uri=mongodb://192.168.101.27:27017/?replicaSet=rs0
name=source.mongo_connector.todo.v2
value.converter=org.apache.kafka.connect.storage.StringConverter
key.converter=org.apache.kafka.connect.storage.StringConverter
poll.max.batch.size=1000

Struct{}Để sử lý struct{}
bạn có thể tham khảo link dưới:
https://nimtechnology.com/2022/02/20/kafka-connect-single-message-transform-lesson-2-valuetokey-and-extractfield-in-sink
https://docs.confluent.io/platform/current/connect/transforms/extractfield.html#examples
Đó là phần ExtractField
connector.class=com.mongodb.kafka.connect.MongoSourceConnector
tasks.max=1
transforms.ExtractField.field=documentKey._id
batch.size=0
change.stream.full.document=updateLookup
transforms=ExtractField
collection=newtodo
output.schema.key={"type":"record","name":"id","fields":[{"name":"documentKey._id","type":"string"}]}
output.format.key=schema
database=todo
topic.prefix=mongov2
poll.await.time.ms=5000
connection.uri=mongodb://192.168.101.27:27017/?replicaSet=rs0
name=source.mongo_connector.todo.v2
value.converter=org.apache.kafka.connect.storage.StringConverter
key.converter=org.apache.kafka.connect.storage.StringConverter
poll.max.batch.size=1000
transforms.ExtractField.type=org.apache.kafka.connect.transforms.ExtractField$Key

connector.class=com.mongodb.kafka.connect.MongoSourceConnector
tasks.max=1
transforms.ExtractField.field=documentKey._id
batch.size=0
change.stream.full.document=updateLookup
transforms=ExtractField
collection=newtodo
output.schema.key={"type":"record","name":"id","fields":[{"name":"documentKey._id","type":"string"}]}
output.format.key=schema
database=todo
topic.prefix=mongov2
poll.await.time.ms=5000
connection.uri=mongodb://192.168.101.27:27017/?replicaSet=rs0
name=source.mongo_connector.todo.v2
value.converter=org.apache.kafka.connect.json.JsonConverter
key.converter=org.apache.kafka.connect.json.JsonConverter
poll.max.batch.size=1000
transforms.ExtractField.type=org.apache.kafka.connect.transforms.ExtractField$Key

connector.class=com.mongodb.kafka.connect.MongoSourceConnector
tasks.max=1
transforms.ExtractField.field=documentKey._id
batch.size=0
change.stream.full.document=updateLookup
transforms=ExtractField
collection=newtodo
output.schema.key={"type":"record","name":"id","fields":[{"name":"documentKey._id","type":"string"}]}
output.format.key=schema
key.converter.schemas.enable=false
database=todo
topic.prefix=mongov2
poll.await.time.ms=5000
connection.uri=mongodb://192.168.101.27:27017/?replicaSet=rs0
name=source.mongo_connector.todo.v2
value.converter.schemas.enable=false
value.converter=org.apache.kafka.connect.json.JsonConverter
key.converter=org.apache.kafka.connect.json.JsonConverter
poll.max.batch.size=1000
transforms.ExtractField.type=org.apache.kafka.connect.transforms.ExtractField$Key

connector.class=com.mongodb.kafka.connect.MongoSourceConnector
tasks.max=1
transforms.ExtractField.field=documentKey._id
batch.size=0
change.stream.full.document=updateLookup
transforms=ExtractField
collection=newtodo
output.schema.key={"type":"record","name":"id","fields":[{"name":"documentKey._id","type":"string"}]}
output.format.key=schema
key.converter.schemas.enable=false
database=todo
topic.prefix=mongov2
poll.await.time.ms=5000
connection.uri=mongodb://192.168.101.27:27017/?replicaSet=rs0
name=source.mongo_connector.todo.v2
value.converter.schemas.enable=false
value.converter=org.apache.kafka.connect.storage.StringConverter
key.converter=org.apache.kafka.connect.storage.StringConverter
poll.max.batch.size=1000
transforms.ExtractField.type=org.apache.kafka.connect.transforms.ExtractField$Key

2) using ValueToKey
transforms.insertKey.fields: documentKey
transforms.insertKey.type: org.apache.kafka.connect.transforms.ValueToKey
transforms:insertKey
Bạn có thể tham khảo thêm 1 bài viết của mình:
https://nimtechnology.com/2022/02/20/kafka-connect-single-message-transform-lesson-2-valuetokey-and-extractfield-in-sink/