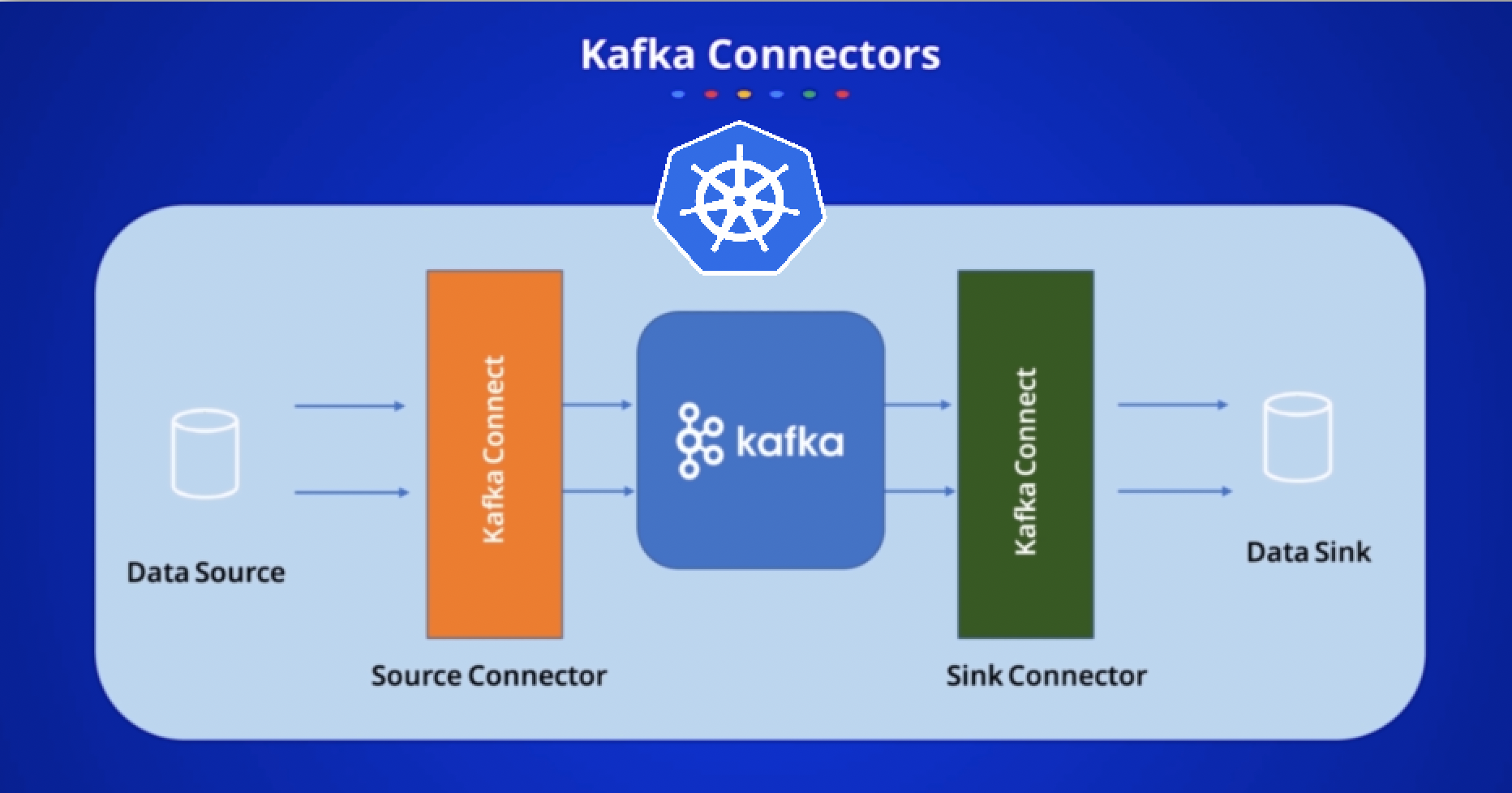
Khi data trong 1 topic ở format Avro,… mà ta muốn sink vào DB thì nó sẽ bị lỗi ở việc tạo field column cho 1 table.
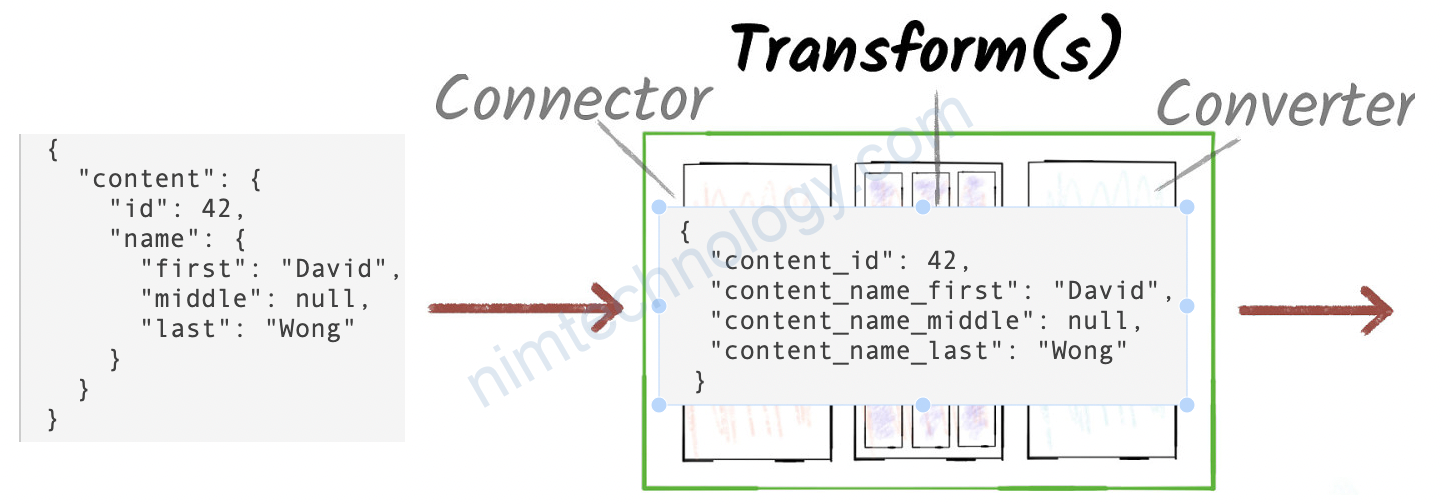
để có thể các field comlumn
1) Setup the components.
Phần setup kafka, bạn có thể coi lại link này he:
Setup the needing components of Kafka
2) Practice.
Launch ksqlDB:
docker exec -it ksqldb bash -c 'echo -e "\n\n⏳ Waiting for ksqlDB to be available before launching CLI\n"; while : ; do curl_status=$(curl -s -o /dev/null -w %{http_code} http://ksqldb:8088/info) ; echo -e $(date) " ksqlDB server listener HTTP state: " $curl_status " (waiting for 200)" ; if [ $curl_status -eq 200 ] ; then break ; fi ; sleep 5 ; done ; ksql http://ksqldb:8088'OK giờ bạn thấy output khá đẹp:

Create a stream:
CREATE STREAM CUSTOMERS (ID BIGINT KEY, FULL_NAME VARCHAR, ADDRESS STRUCT<STREET VARCHAR, CITY VARCHAR, COUNTY_OR_STATE VARCHAR, ZIP_OR_POSTCODE VARCHAR>)
WITH (KAFKA_TOPIC='day3-customers',
VALUE_FORMAT='AVRO',
REPLICAS=1,
PARTITIONS=4);

chúng ta có thế show topic trong ksql:show topics;

preview data:
docker exec kafkacat kafkacat -b broker:29092 -r http://schema-registry:8081 -s key=s -s value=avro -t day3-customers -C -c1 -o beginning -u -q -J | jq '.'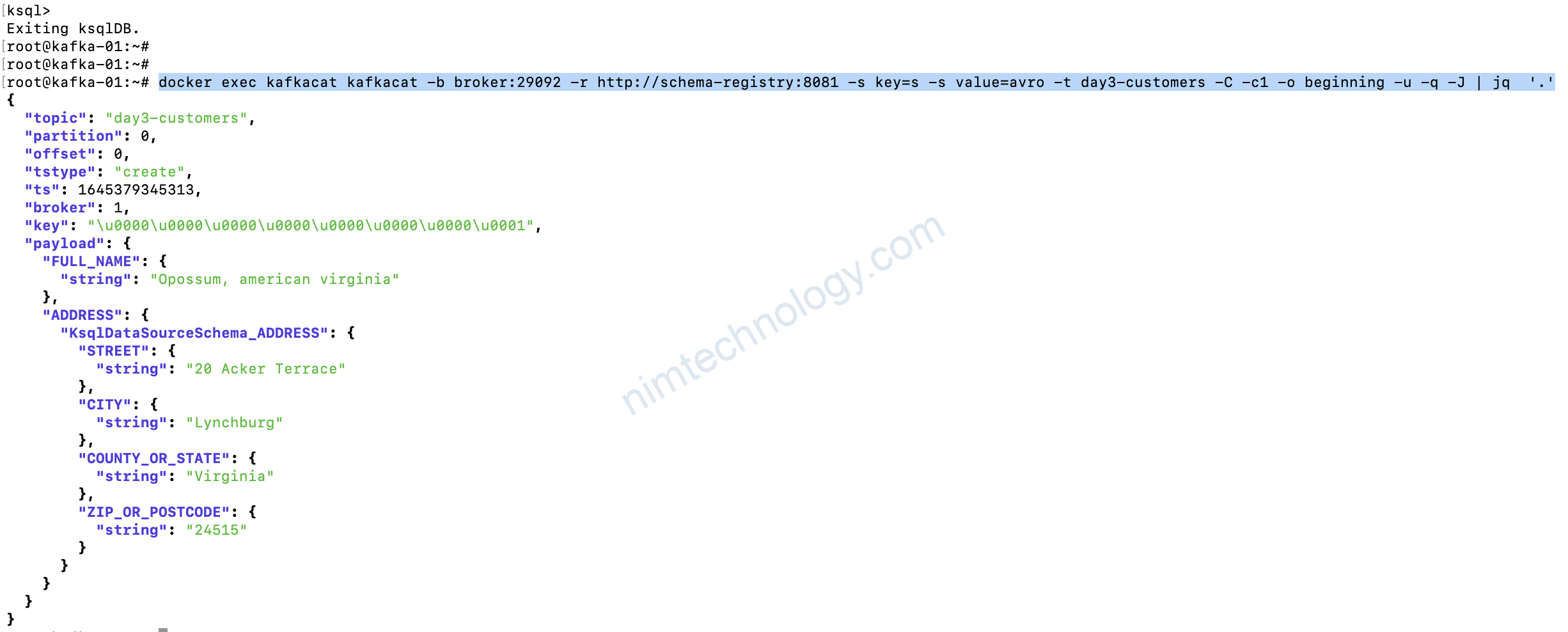
Bạn có thể thấy key đã được serialize"key": "\u0000\u0000\u0000\u0000\u0000\u0000\u0000\u0001",
Giờ chúng ta tạo 1 jdbc sink connector:
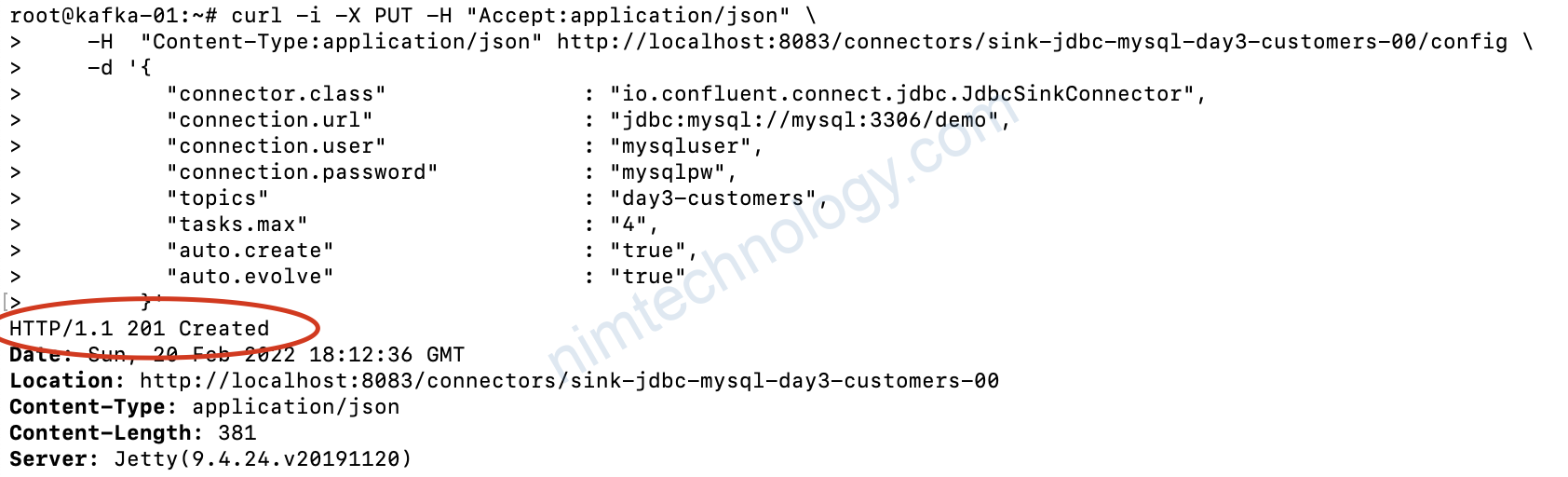
curl -i -X PUT -H "Accept:application/json" \
-H "Content-Type:application/json" http://localhost:8083/connectors/sink-jdbc-mysql-day3-customers-00/config \
-d '{
"connector.class" : "io.confluent.connect.jdbc.JdbcSinkConnector",
"connection.url" : "jdbc:mysql://mysql:3306/demo",
"connection.user" : "mysqluser",
"connection.password" : "mysqlpw",
"topics" : "day3-customers",
"tasks.max" : "4",
"auto.create" : "true",
"auto.evolve" : "true"
}'
Giờ show status các connector:
curl -s "http://localhost:8083/connectors?expand=info&expand=status" | jq '. | to_entries[] | [ .value.info.type, .key, .value.status.connector.state,.value.status.tasks[].state,.value.info.config."connector.class"]|join(":|:")' | column -s : -t| sed 's/\"//g'| sort
check kĩ task bị lỗi gì:
curl -s "http://localhost:8083/connectors/sink-jdbc-mysql-day3-customers-00/status"| jq '.tasks[0].trace'
Lỗi trên là sink nó ko thể map struct vào trong database
nó kiểu ADDRESS.xxx.xxx
Many databases don’t have support for nested fields, and whilst some have added it in recent times the JDBC Sink connector doesn’t support it.
Stream the nested data to MySQL – with a Flatten SMT
https://docs.confluent.io/platform/current/connect/transforms/flatten.html#avro-example
Bạn nên sem để hiểu các ví dụ nhé
Avro Example
The Avro schema specification only allows alphanumeric characters and the underscore _ character in field names. The configuration snippet below shows how to use Flatten to concatenate field names with the underscore _ delimiter character.
"transforms": "flatten", "transforms.flatten.type": "org.apache.kafka.connect.transforms.Flatten$Value", "transforms.flatten.delimiter": "_"
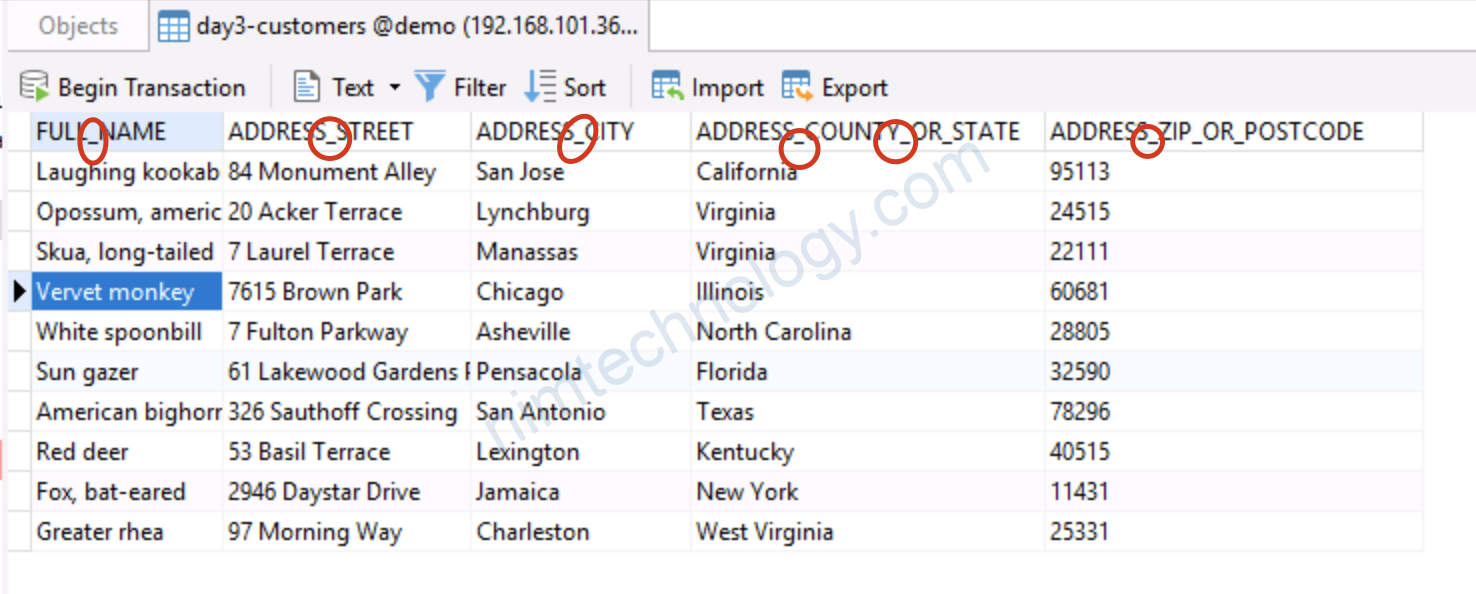
Before:
{
"content": {
"id": 42,
"name": {
"first": "David",
"middle": null,
"last": "Wong"
}
}
}
After:
{
"content_id": 42,
"content_name_first": "David",
"content_name_middle": null,
"content_name_last": "Wong"
}
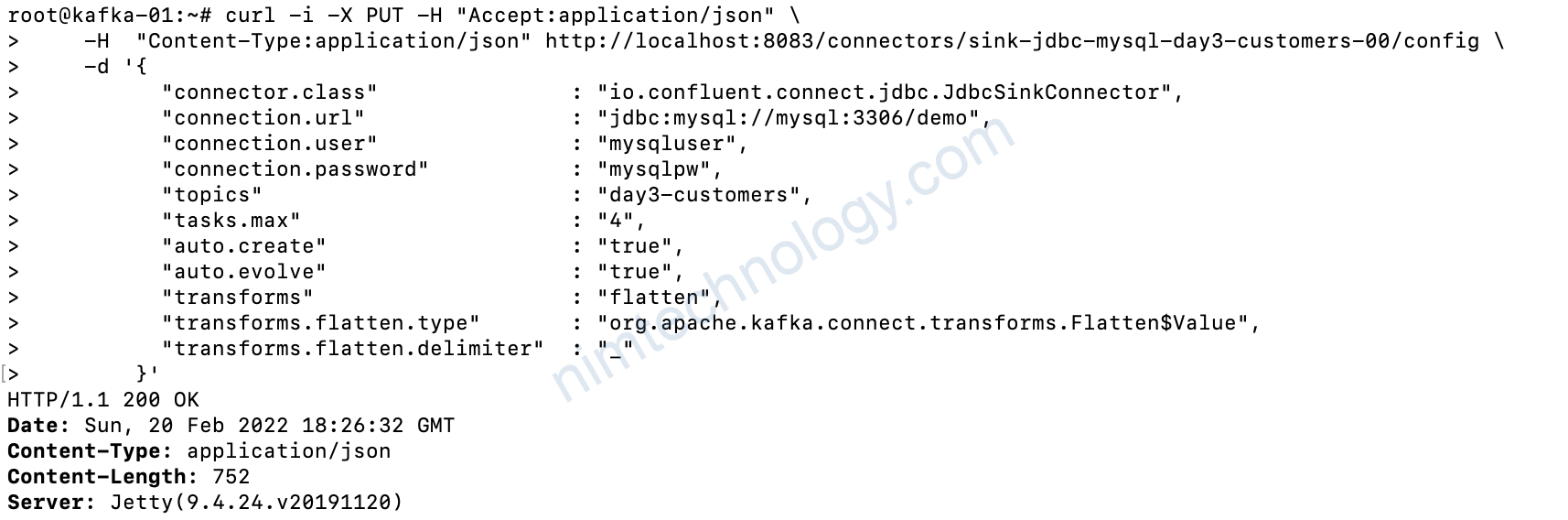
curl -i -X PUT -H "Accept:application/json" \
-H "Content-Type:application/json" http://localhost:8083/connectors/sink-jdbc-mysql-day3-customers-00/config \
-d '{
"connector.class" : "io.confluent.connect.jdbc.JdbcSinkConnector",
"connection.url" : "jdbc:mysql://mysql:3306/demo",
"connection.user" : "mysqluser",
"connection.password" : "mysqlpw",
"topics" : "day3-customers",
"tasks.max" : "4",
"auto.create" : "true",
"auto.evolve" : "true",
"transforms" : "flatten",
"transforms.flatten.type" : "org.apache.kafka.connect.transforms.Flatten$Value",
"transforms.flatten.delimiter" : "_"
}'

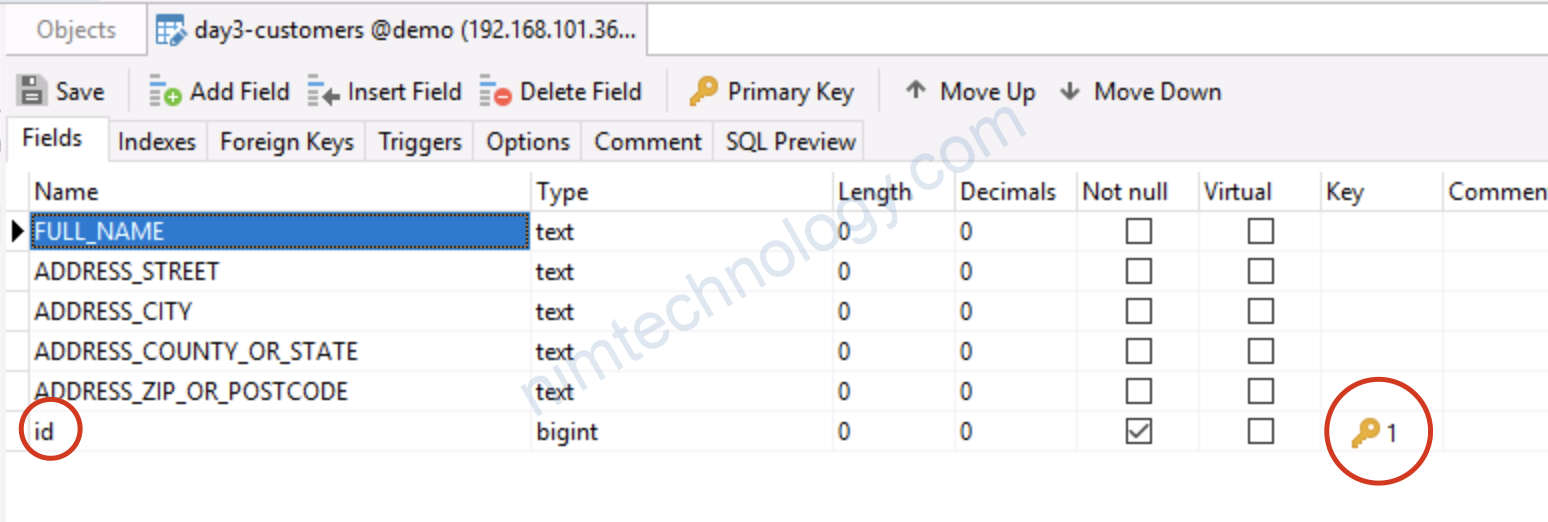
Add thêm khoá vào bảng
Here’s how to add the key into the target table:
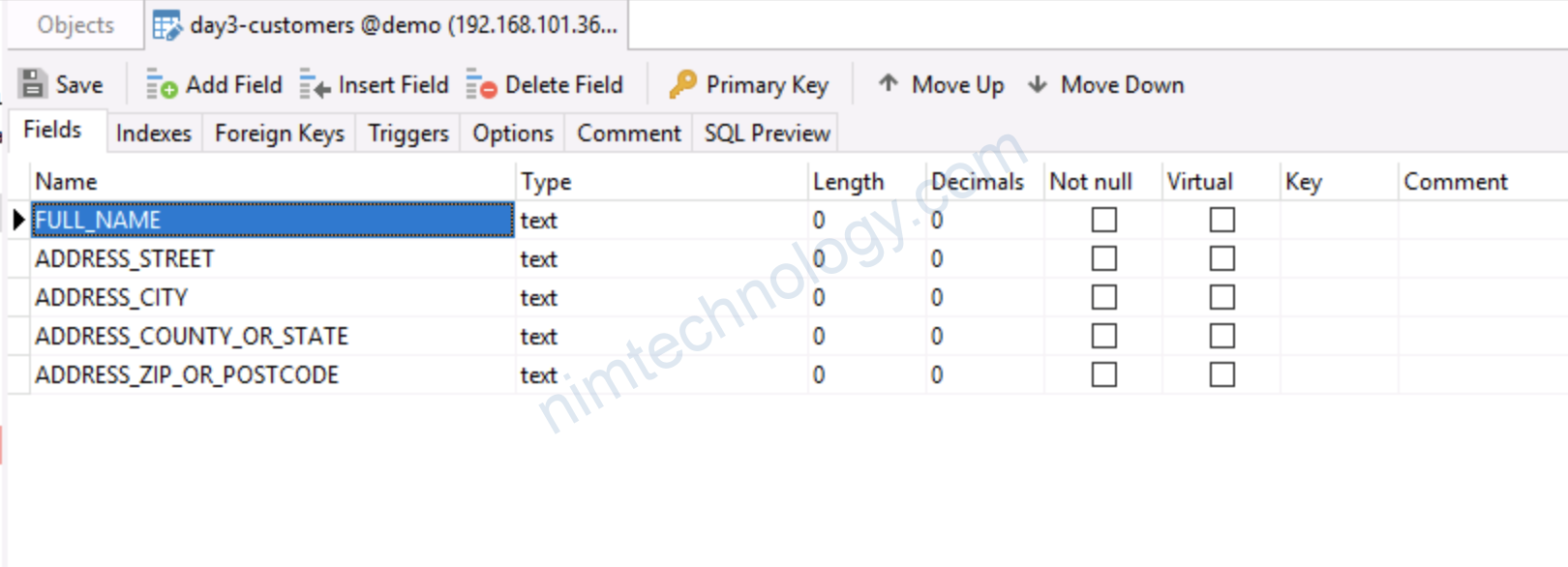
Chúng ta sẽ sử dụng:
“key.converter” : “org.apache.kafka.connect.converters.LongConverter”
Use LongConverter to deserialize that in kafka-connect
“pk.mode” : “record_key”,
Tell the JdbcSinkConnector that Primary key handling in the database, use the key of the Kafka message
“pk.fields” : “id”,
Chúng ta nói JdbcSinkConnector với field hay comlumn thì đánh khoá chính trong dabase
Giờ bạn cần xoá table day3-customers trong database mysql
xoá connector
curl -i -X DELETE -H "Accept:application/json" -H "Content-Type:application/json" http://localhost:8083/connectors/sink-jdbc-mysql-day3-customers-00Giờ tạo lại connector
curl -i -X PUT -H "Accept:application/json" \
-H "Content-Type:application/json" http://localhost:8083/connectors/sink-jdbc-mysql-day3-customers-02/config \
-d '{
"connector.class" : "io.confluent.connect.jdbc.JdbcSinkConnector",
"connection.url" : "jdbc:mysql://mysql:3306/demo",
"connection.user" : "mysqluser",
"connection.password" : "mysqlpw",
"topics" : "day3-customers",
"tasks.max" : "4",
"auto.create" : "true",
"auto.evolve" : "true",
"transforms" : "flatten",
"transforms.flatten.type" : "org.apache.kafka.connect.transforms.Flatten$Value",
"transforms.flatten.delimiter" : "_",
"pk.mode" : "record_key",
"pk.fields" : "id",
"key.converter" : "org.apache.kafka.connect.converters.LongConverter"
}'