1) look into Fluent Bit.
Đầu tiên chúng ta tìm hiểu về fluent bit.

Bạn có thể coi video này để hiểu một chút về fluent Bit.
Fluent Bit được việt bằng C nên là nó rất nhẹ.
1.1) Fluent Bit’s configuration file
trong 1 main configuration file thì gồm 1 sections.
- Service: The Service section defines the global configuration for Fluent Bit. It contains parameters that control the general behavior of the application, such as logging level, flush intervals, and other options. Some common configuration options in the Service section include:
- Flush: The interval (in seconds) for the data flush to the output plugins.
- Daemon: Controls if Fluent Bit should run as a daemon (background process) or not.
- Log_Level: Specifies the logging verbosity (error, warning, info, or debug).
- When you set
Log_Level: infoin the Fluent Bit configuration, you are defining the minimum log level that Fluent Bit will display or process in its own internal logs. It means that Fluent Bit will log messages with a level of “info” or higher (i.e., “info,” “warning,” and “error”).
- When you set
- Input: The Input section defines the data sources that Fluent Bit will collect data from. Fluent Bit supports various input plugins to collect data from different sources like log files, system metrics, network data, etc. Each input plugin has its own set of configuration options. Some commonly used input plugins are:
- Tail: Reads log files and watches for new lines appended in real-time.
- Syslog: Collects data from Syslog messages over the network (TCP/UDP).
- CPU: Gathers CPU usage metrics.
- Filter: The Filter section is used to modify or enrich the collected data before it is sent to the output destination. Filters can be used for various purposes such as adding, modifying, or removing specific fields, as well as performing transformations on the data. Fluent Bit offers several filter plugins, including:
- Kubernetes: Enhances logs with Kubernetes metadata.
- Record Modifier: Modifies records by adding, removing, or renaming fields.
- Lua: Executes Lua scripts to manipulate records.
- Output: The Output section defines the destination where the processed data will be sent. Fluent Bit supports a wide range of output plugins to ship data to various services and systems, including databases, cloud services, and other log collectors. Each output plugin has its configuration options. Some popular output plugins are:
- Elasticsearch: Sends data to an Elasticsearch cluster.
- Kafka: Forwards data to Apache Kafka.
- HTTP: Sends data via HTTP/HTTPS to a remote endpoint.
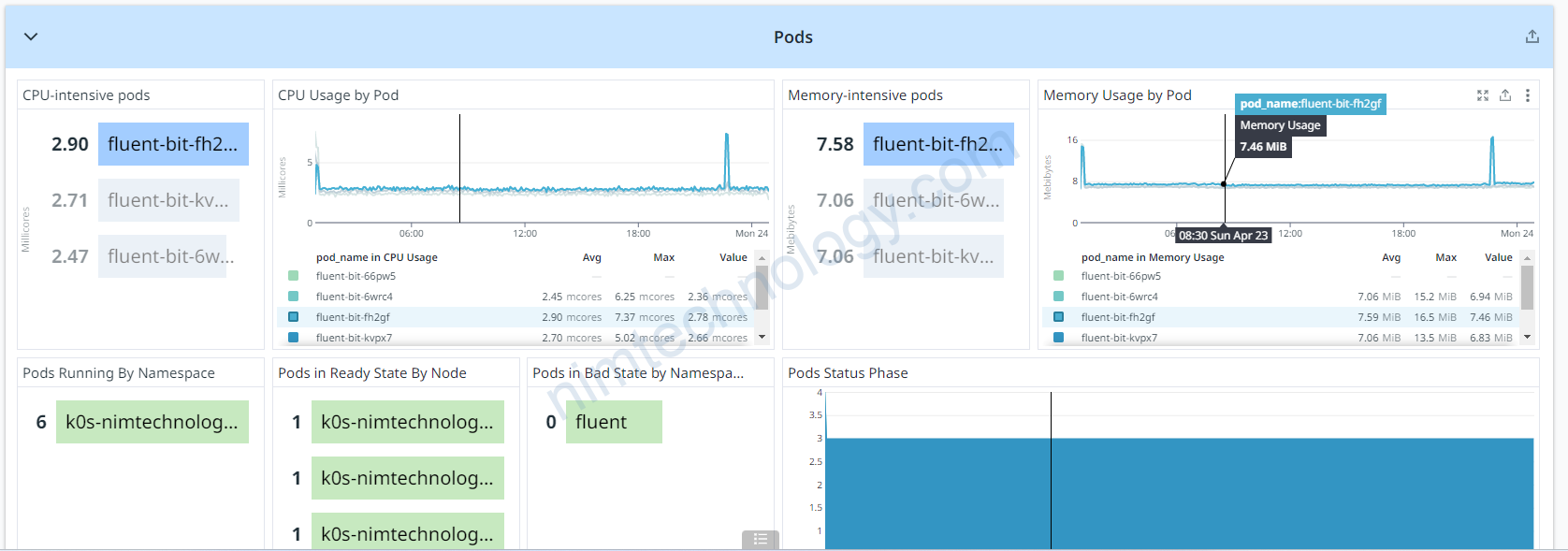
Chúng ta sẽ đến 1 ví dụ fluent bit lấy log stdout
Below is a sample Fluent Bit configuration to collect logs from Kubernetes containers (stdout), enhance the logs with Kubernetes metadata, and then forward the logs to an Elasticsearch cluster. The configuration file is divided into four main sections: Service, Input, Filter, and Output.
[SERVICE]
Flush 1
Daemon Off
Log_Level info
Parsers_File parsers.conf
[INPUT]
Name tail
Tag kube.*
Path /var/log/containers/*.log
Parser docker
DB /var/log/flb_kube.db
Mem_Buf_Limit 5MB
Skip_Long_Lines On
Refresh_Interval 10
[FILTER]
Name kubernetes
Match kube.*
Kube_URL https://kubernetes.default.svc:443
Kube_CA_File /var/run/secrets/kubernetes.io/serviceaccount/ca.crt
Kube_Token_File /var/run/secrets/kubernetes.io/serviceaccount/token
Merge_Log On
K8S-Logging.Parser On
K8S-Logging.Exclude Off
[OUTPUT]
Name elasticsearch
Match kube.*
Host ${FLUENT_ELASTICSEARCH_HOST}
Port ${FLUENT_ELASTICSEARCH_PORT}
Logstash_Format On
Retry_Limit False
Replace_Dots On
Explanation of each section and their configurations:
- Service:
- Flush: The interval (in seconds) for the data flush to the output plugins, set to 1 second.
- Daemon: Fluent Bit will not run as a daemon (background process) in this case.
- Log_Level: The logging verbosity is set to “info” level.
- Parsers_File: Specifies the file containing parsers for different log formats, such as “docker” in this example.
- Input:
- Name: The input plugin used is “tail,” which reads log files and watches for new lines appended in real-time.
- Tag: A tag (“kube.*”) is assigned to the logs for matching with Filter and Output sections.
- Path: The path to Kubernetes container log files.
- Parser: The “docker” parser is used to parse logs in the Docker JSON format.
- DB: A SQLite database file to keep track of the monitored files and their offsets.
- Mem_Buf_Limit: The memory buffer size limit set to 5MB.
- Skip_Long_Lines: Skips lines that are longer than the buffer size to avoid breaking the parser.
- Refresh_Interval: The interval (in seconds) to refresh the monitored files list, set to 10 seconds.
- Filter:
- Name: The “kubernetes” filter plugin is used to enhance logs with Kubernetes metadata.
- Match: The filter is applied to logs with the tag “kube.*”.
- Kube_URL: The URL to access the Kubernetes API server.
- Kube_CA_File: The path to the Kubernetes API server’s CA certificate file.
- Kube_Token_File: The path to the Kubernetes service account token file for authentication.
- Merge_Log: Indicates whether to merge the log content with the Kubernetes metadata.
- K8S-Logging.Parser: Enables automatic parser assignment based on Kubernetes container annotations.
- K8S-Logging.Exclude: Disables the exclusion of logs based on Kubernetes container annotations.
- Output:
- Name: The output plugin used is “elasticsearch” to send data to an Elasticsearch cluster.
- Match: The output plugin processes logs with the tag “kube.*”.
- Host: The Elasticsearch host address, usually passed as an environment variable.
- Port: The Elasticsearch port, also passed