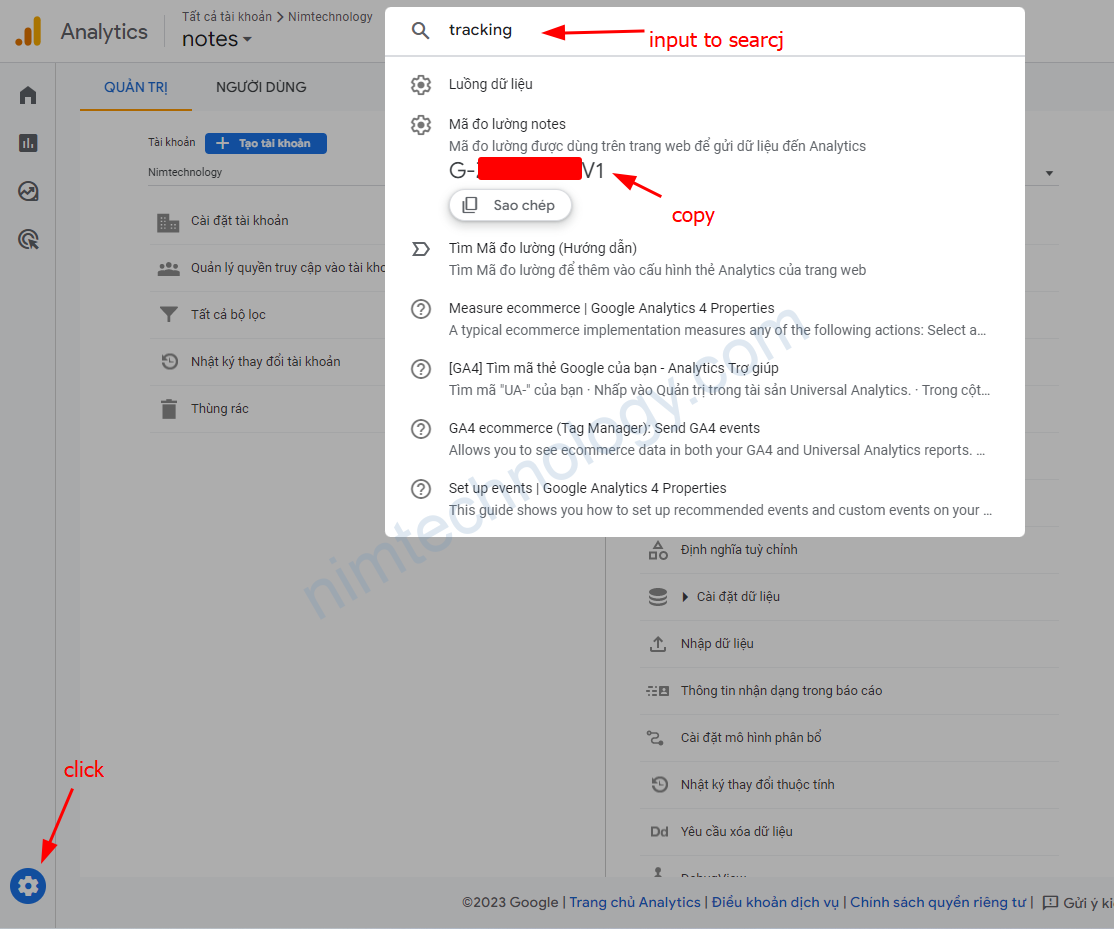
Explore full and incremental backups.
Câu trả lời ngắn là: có thể có với file ảnh hoặc thư mục nếu bạn backup theo kiểu thủ công, nhưng với MySQL thì thường không xảy ra nếu bạn làm đúng quy trình full backup + binary log.
Nhiều người nghe đến “full backup rồi incremental backup” thường lo một chuyện rất thực tế: bản full chứa dữ liệu từ trước đến nay, vậy nếu sau này có file bị xóa, đến lúc restore từ full + incremental thì các file cũ đó có sống lại và làm dữ liệu bị rác không? Câu hỏi này hoàn toàn hợp lý, nhưng đáp án lại khác nhau giữa backup file và backup database.
Trước hết, hiểu đúng về full và incremental.
Full backup là bản sao toàn bộ dữ liệu tại một thời điểm, còn incremental backup chỉ lưu phần thay đổi kể từ lần backup trước đó hoặc từ mốc được công cụ quy định. Với backup file, các công cụ như GNU tar có hỗ trợ incremental dumps; còn với file server, rsync kết hợp hard-link là một cách rất phổ biến để tạo các điểm backup theo thời gian.
Vì sao file đã xóa có thể quay lại khi restore?
Điều này xảy ra khi bạn làm backup theo kiểu “full một cục, incremental một cục”, rồi đến lúc phục hồi thì giải nén bản full trước, sau đó chồng các bản incremental lên trên. Trong mô hình này, nếu bản incremental chỉ chứa file mới hoặc file sửa đổi mà không thể hiện rõ trạng thái “file này đã bị xóa”, thì file cũ từ bản full vẫn còn nguyên sau khi restore và tạo cảm giác dữ liệu bị rác.
Ví dụ rất dễ hình dung:
- Ngày 1, thư mục ảnh có
a.jpgvàb.jpg, bạn tạo full backup. - Ngày 2, bạn xóa
a.jpgvà thêmc.jpg. - Ngày 3, bạn restore bằng cách bung full backup rồi chép thêm phần incremental.
Nếu công cụ backup của bạn chỉ lưu phần “thêm mới/thay đổi” mà không quản lý tốt trạng thái xóa, kết quả sau restore có thể thành a.jpg, b.jpg, c.jpg. Trong khi thực tế ở thời điểm cần khôi phục, a.jpg đã không còn nữa.
Đây là chỗ nhiều người bị nhầm:
Không phải cứ incremental backup là sai, mà sai ở cách thiết kế cơ chế restore. Nếu backup chỉ là các gói dữ liệu chồng lớp, không có cơ chế snapshot hoặc state tracking, chuyện file đã xóa quay lại là hoàn toàn có thể xảy ra.
Với MySQL thì câu chuyện lại khác.
MySQL incremental backup thường dựa trên binary log, tức là nhật ký ghi lại các thay đổi trong database theo thời gian. Công cụ mysqlbinlog được dùng để xử lý hoặc phát lại các binary log này khi cần phục hồi dữ liệu.
Điểm quan trọng là binary log không chỉ ghi thêm dữ liệu mới, mà còn ghi cả các thao tác như INSERT, UPDATE, và DELETE. Vì vậy, nếu trong thời gian vận hành bạn đã xóa một bản ghi, thao tác xóa đó cũng nằm trong chuỗi log và sẽ được áp lại trong quá trình restore.
Hãy hình dung như sau:
- Thứ Hai, bạn tạo full backup bằng
mysqldump. - Thứ Ba, người dùng thêm dữ liệu mới.
- Thứ Tư, một số bản ghi cũ bị xóa.
- Thứ Năm, bạn cần restore.
Quy trình đúng sẽ là:
- Phục hồi bản full backup trước.
- Phát lại binary log từ sau thời điểm full backup.
Ở bước đầu, dữ liệu cũ có thể xuất hiện trở lại vì bạn vừa nạp bản full của quá khứ. Nhưng đến bước phát lại log, các lệnh xóa đã từng diễn ra cũng được chạy lại, nên trạng thái cuối cùng của database sẽ khớp với mốc thời gian bạn muốn phục hồi.
Nói cách khác, với MySQL làm đúng chuẩn thì restore không phải là “bung full rồi chồng thêm file”, mà là “phục hồi mốc nền rồi phát lại lịch sử thay đổi”. Đó là lý do vì sao nỗi lo “restore xong dữ liệu cũ sống lại thành rác” thường đúng với backup file kiểu thô sơ, nhưng không đúng với MySQL khi dùng full backup kết hợp binary log.
Vậy nên backup thế nào để dễ restore và ít rủi ro nhất?
- Với file ảnh, không nên chỉ nén
tarhoặcziptheo kiểu chắp vá rồi khi cần thì giải nén chồng lên nhau. Cách an toàn hơn là dùng rsync kết hợp hard-link hoặc các công cụ snapshot để mỗi mốc backup nhìn giống như một bản full hoàn chỉnh của riêng ngày đó. - Với MySQL, nên dùng full backup định kỳ bằng
mysqldump, sau đó giữ binary log để có thể restore đến một thời điểm cụ thể.mysqldumpvới các tùy chọn như--single-transaction --quickthường được dùng để backup InnoDB ổn định hơn trên hệ thống đang chạy. - Với cả hai loại dữ liệu, đừng chỉ quan tâm chuyện backup có chạy hay không; điều quan trọng hơn là phải kiểm tra restore định kỳ. Một bản backup chỉ thực sự có giá trị khi khôi phục lại được đầy đủ và đúng trạng thái mong muốn.
Một nguyên tắc rất thực dụng mà ai làm hệ thống cũng nên nhớ:
Backup để “có file lưu” chưa đủ. Mục tiêu thật sự là restore đúng, sạch, đủ và nhanh.
Nếu bạn backup file ảnh, hãy nghĩ theo hướng “mỗi mốc là một snapshot có thể lấy ra dùng ngay”. Nếu bạn backup MySQL, hãy nghĩ theo hướng “full backup là nền, còn binary log là lịch sử thay đổi”. Khi hiểu đúng hai ý này, bạn sẽ không còn bị lẫn giữa backup file và backup database nữa.
Ghi chú đăng bài
Bạn có thể giữ nguyên bài này để đăng blog, hoặc xóa các ký hiệu nguồn như [web:40] trước khi xuất bản cho gọn hơn. Nếu cần, tôi có thể viết tiếp cho bạn một bản khác theo giọng văn chuyên nghiệp hơn, hoặc một bản ngắn gọn kiểu “chia sẻ kinh nghiệm thực chiến” để hợp blog cá nhân hơn.
How often should a full backup be run?
Không có con số cố định, mà phụ thuộc vào quy mô dữ liệu và mức độ quan trọng của hệ thống. Các mô hình phổ biến hiện nay là:
| Tần suất Full Backup | Phù hợp với | Recovery Point |
|---|---|---|
| Hàng ngày | DB nhỏ, hệ thống tài chính, healthcare | Tối đa 24 giờ mất dữ liệu |
| Hàng tuần | Production DB vừa, file server doanh nghiệp | Kết hợp incremental hàng ngày |
| Hàng tháng | Data warehouse, cold storage lớn | Kết hợp weekly differential |
Cơ chế merge: “Ép” full + incremental thành full mới
Câu hỏi này rất kỹ thuật và thực ra có cơ chế để làm điều đó, gọi là Synthetic Full Backup.
Synthetic Full Backup là gì?
Thay vì đọc dữ liệu từ server gốc như full backup truyền thống, công cụ sẽ đọc bản full cũ + tất cả các incremental từ storage, sau đó ghép chúng lại thành một file full backup mới hoàn toàn.
Ví dụ cụ thể:
textFull (Thứ 2) + Incr (T3) + Incr (T4) + Incr (T5)
↓ Synthetic Full
Full MỚI (Thứ 5) ← hoàn chỉnh, sạch, không rác
Ưu điểm lớn nhất: Server gốc không cần làm gì (zero load), vì công cụ tự xử lý ở tầng storage.
Lưu ý: Cần dư dung lượng bằng ít nhất 1 lần kích thước full backup để tạo file tạm trong quá trình merge.
Ngoài thực tế, người ta đang làm gì?
Chiến lược GFS (Grandfather-Father-Son)
Đây là tiêu chuẩn phổ biến nhất trong doanh nghiệp hiện nay:
- Son (Con): Backup incremental mỗi ngày. Giữ lại 7 ngày gần nhất.
- Father (Cha): Backup full mỗi tuần (thường Chủ Nhật). Giữ lại 4 tuần.
- Grandfather (Ông): Backup full mỗi tháng. Giữ lại 12 tháng.
Khi bản Son/Father hết hạn giữ, chúng bị xóa. Bản Grandfather thường được đẩy lên cloud hoặc lưu offline dài hạn.
Với MySQL cụ thể
Không cần merge phức tạp. Quy trình chuẩn là:
- Hàng tuần: Chạy
mysqldumptạo bản full mới → đây trở thành “nền mới”. - Hàng ngày: Binary log tiếp tục ghi incremental từ mốc full mới đó.
- Sau khi full mới đã verify thành công, xóa bản full cũ và binlog trước thời điểm full mới.
Công cụ Synthetic Full phổ biến
- Veeam: Tự động tạo synthetic full theo lịch, gần như zero-touch.
- BorgBackup / Restic: Có lệnh
pruneđể tự dọn bản cũ và hợp nhất theo chính sách. - Acronis, Backblaze B2: Tích hợp sẵn cơ chế merge incremental → full theo policy.
Nguyên tắc thực chiến tóm gọn
- Đừng để chuỗi incremental quá dài (thường không quá 7 ngày) vì restore sẽ chậm và rủi ro cao nếu một file trong chuỗi bị hỏng.
- Kết hợp GFS + Synthetic Full là cách hiện đại nhất: tự động gộp, tự động xóa cũ, không cần can thiệp thủ công.
- Test restore ít nhất 1 lần/tháng từ bản full mới tổng hợp để đảm bảo nó thực sự dùng được.