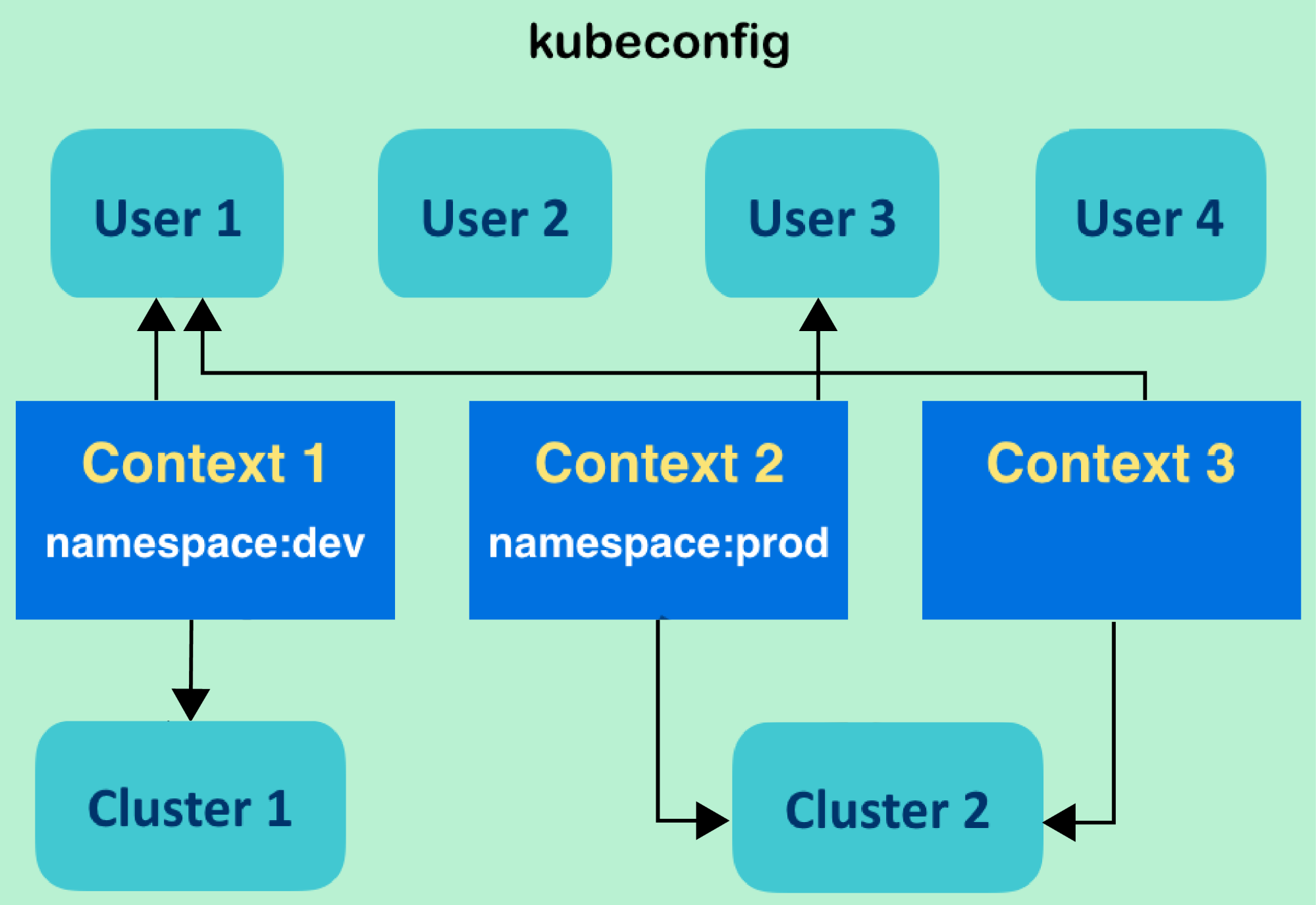
Trong môi trường Amazon EKS (Elastic Kubernetes Service) kết hợp với AWS Load Balancer Controller, Ingress có hai chế độ (mode) chính để định tuyến (route) traffic từ Application Load Balancer (ALB) vào trong cluster: Instance mode (NodePort) và IP mode (Pod IP).
Dưới đây là so sánh chi tiết giữa hai cách tiếp cận này để bạn dễ dàng trao đổi với Tech Lead về góc độ kiến trúc mạng và hiệu năng.
1. Chế độ Instance (NodePort)
Ở chế độ mặc định này, ALB sẽ coi các EC2 Worker Node trong EKS cluster là các target.platform9+1
- Luồng đi của dữ liệu (Traffic flow): Client -> ALB -> Node IP : NodePort -> kube-proxy (iptables/IPVS) -> Pod IP.
- Cơ chế hoạt động: Kube-proxy mở một cổng ngẫu nhiên (từ 30000 – 32767) trên tất cả các EC2 Node. ALB gửi request vào cổng này trên bất kỳ Node nào. Sau đó, iptables của Node đó sẽ tiếp tục NAT (Network Address Translation) và định tuyến request đến một Pod ngẫu nhiên nằm trong cluster (Pod này có thể nằm trên chính Node đó hoặc nằm ở một Node khác).
- Ưu điểm:
- Nhược điểm (Điểm trừ kỹ thuật lớn):
- Thêm một bước nhảy mạng (Extra network hop): Traffic đến Node A nhưng Pod xử lý có thể nằm ở Node B, dẫn đến tăng độ trễ (latency) và tốn chi phí truyền tải data giữa các Node (cross-node traffic).
- Mất Source IP của Client: Do bị SNAT qua kube-proxy, Pod sẽ thấy IP nguồn là IP của EC2 Node thay vì IP thật của người dùng (trừ khi dùng
externalTrafficPolicy: Local, nhưng lại gây mất cân bằng tải). - Phức tạp Security Group: Phải mở dải port rộng (30000-32767) trên EC2 Security Group để ALB gọi vào.
2. Chế độ IP (Pod IP)
Ở chế độ này, ALB bỏ qua hoàn toàn EC2 Node và giao tiếp trực tiếp với IP của từng Pod. Bắt buộc phải cấu hình chú thích (annotation) alb.ingress.kubernetes.io/target-type: ip trong Ingress.
- Luồng đi của dữ liệu: Client -> ALB -> Pod IP (Bỏ qua hoàn toàn kube-proxy và NodePort).
- Cơ chế hoạt động: Nhờ AWS VPC CNI, mỗi Pod trong EKS được cấp một địa chỉ IP thật (Routable IP) nằm ngay trong VPC. AWS Load Balancer Controller sẽ đọc danh sách IP của các Pod này và tự động đăng ký (register) chúng trực tiếp vào Target Group của ALB.
- Ưu điểm (Lý do các hệ thống lớn ưa chuộng):
- Độ trễ tối thiểu (Low Latency): Không có “bước nhảy mạng” (hop) thừa, không đi qua iptables của kube-proxy, traffic đi thẳng từ ALB vào thẳng Container.
- Giữ nguyên Client IP: Pod nhận được chính xác IP gốc của người dùng, cực kỳ hữu ích cho việc rate-limit, tracking hoặc làm rule Firewall.[platform9]
- Tối ưu Load Balancing: ALB dùng thuật toán Round Robin chia tải đều trực tiếp cho từng Pod, giải quyết triệt để tình trạng một Node bị quá tải do kube-proxy điều phối không đều.[platform9]
- Nhược điểm:
Bảng đúc kết quyết định kiến trúc
| Tiêu chí | IP Mode (Pod IP) | Instance Mode (NodePort) |
|---|
| Tiêu chí | IP Mode (Pod IP) | Instance Mode (NodePort) |
|---|---|---|
| Độ trễ (Latency) | Cực thấp (Đi thẳng vào Pod) [platform9] | Cao hơn (Đi qua Kube-proxy & NAT) devopsviet+1 |
| Phân bổ tải (Load Balancing) | Hoàn hảo (Chia đều từng Pod) [platform9] | Kém đều hơn (Chia theo Node, Node lại chia ngẫu nhiên) devopsviet+1 |
| Client Source IP | Giữ nguyên gốc [platform9] | Bị ẩn dưới IP của Node viblo+1 |
| Yêu cầu Security Group | Mở đúng Port của App (VD: 8080) [howtogeek] | Mở dải port lớn (30000-32767) platform9+1 |
| Khi nào nên dùng? | Lựa chọn số 1 cho Production (Đặc biệt là Microservices cần tối ưu performance) platform9+1 | Khi không dùng AWS VPC CNI hoặc app chỉ chạy nội bộ/Test platform9+1 |
Cách nói chuyện với Tech Lead:
“Đối với EKS, em đề xuất dùng IP Mode cho Ingress thay vì NodePort mặc định. Việc này giúp ALB bắn traffic thẳng vào Pod, bỏ qua khâu NAT của iptables trên Node. Kiến trúc này giải quyết được hai bài toán quan trọng nhất: giảm tối đa latency network và giữ được Source IP thật của user để team Security/Data làm rules. Đổi lại, mình chỉ cần setup dải IP Subnet đủ rộng cho VPC CNI là xong”.
diving deep into pod termination, which is better: Instance mode (NodePort) or IP mode (Pod IP) in EKS ALB?
Hiện tượng rớt gói tin này xảy ra ở cả chế độ NodePort lẫn chế độ IP, thậm chí ở chế độ IP còn dễ rớt gói hơn.
Tại sao lại bị rớt gói tin (Downtime) khi terminate Pod?
Khi K8s nhận lệnh tắt một Pod, nó thực hiện 2 việc song song cùng một lúc:
- Gửi tín hiệu
SIGTERMđến ứng dụng: Báo cho App biết “Hãy tắt đi”. Ứng dụng thường sẽ tự tắt ngay lập tức. - Xóa Pod khỏi mạng lưới định tuyến: Báo cho kube-proxy cập nhật iptables (với NodePort) HOẶC gọi API của AWS để xóa IP của Pod khỏi Target Group của ALB (với IP Mode).
Vấn đề: Bước số 2 mất thời gian để đồng bộ (propagation delay). Trong lúc iptables chưa cập nhật xong hoặc AWS Target Group chưa xóa xong IP, ALB vẫn coi Pod đó là “sống” và tiếp tục ném request mới vào. Nhưng ở bước 1, ứng dụng đã bị SIGTERM giết chết rồi. Kết quả: ALB gọi vào một Pod đã chết $\rightarrow$ rớt gói tin (502).
Cách giải quyết triệt để (Zero-Downtime Deployment)
Để khắc phục 100% hiện tượng này, bạn cần cấu hình chuỗi Graceful Shutdown với 3 bước sau:
1. Thêm preStop hook (Quan trọng nhất)
Bạn cấu hình Pod “ngủ” (sleep) một khoảng thời gian trước khi thực sự nhận tín hiệu tắt.
Mục đích là câu giờ để K8s và AWS Load Balancer Controller có đủ thời gian gỡ IP/NodePort khỏi bộ định tuyến, trong khi ứng dụng vẫn đang chạy bình thường để hứng các request rớt nhịp.
lifecycle:
preStop:
exec:
command: ["/bin/sh", "-c", "sleep 15"]
Hoặc chỗ này bạn discuss với dev chúng ta có giao tiếp với app bằng command hay cách nào đó để có thể thông báo với app là sẽ không nhận request mới, cố gằng hoàn thành request cũ chuyển request cũ qua 1 pod khác bằng cơ chế retry hoặc cached
2. Ứng dụng tự xử lý Graceful Shutdown
Sau khi hết 15 giây sleep, K8s sẽ gửi tín hiệu SIGTERM vào Container. Code của bạn (Node.js, Go, Java…) phải bắt (catch) được tín hiệu này và:
- Ngừng nhận request mới.
- Xử lý cho xong các request cũ đang chạy dở.
- Đóng kết nối Database an toàn rồi mới exit.
3. Tinh chỉnh terminationGracePeriodSeconds
K8s mặc định chỉ cho Pod 30 giây để hoàn thành quá trình tắt. Nếu cấu hình preStop là 15 giây, ứng dụng chỉ còn 15 giây để dọn dẹp. Nếu xử lý lâu hơn, K8s sẽ gửi SIGKILL giết chết Pod ngay lập tức gây đứt kết nối. Hãy tăng con số này lên cho an toàn.
terminationGracePeriodSeconds: 604. Giảm Deregistration Delay trên ALB (Dành riêng cho Ingress ALB)
Mặc định ALB giữ target ở trạng thái “draining” trong 300 giây (5 phút). Bạn nên dùng annotation trên Ingress để giảm con số này xuống mức hợp lý (ví dụ 30 giây) để ALB nhả kết nối nhanh hơn, khớp với vòng đời của Pod.
alb.ingress.kubernetes.io/target-group-attributes: deregistration_delay.timeout_seconds=30