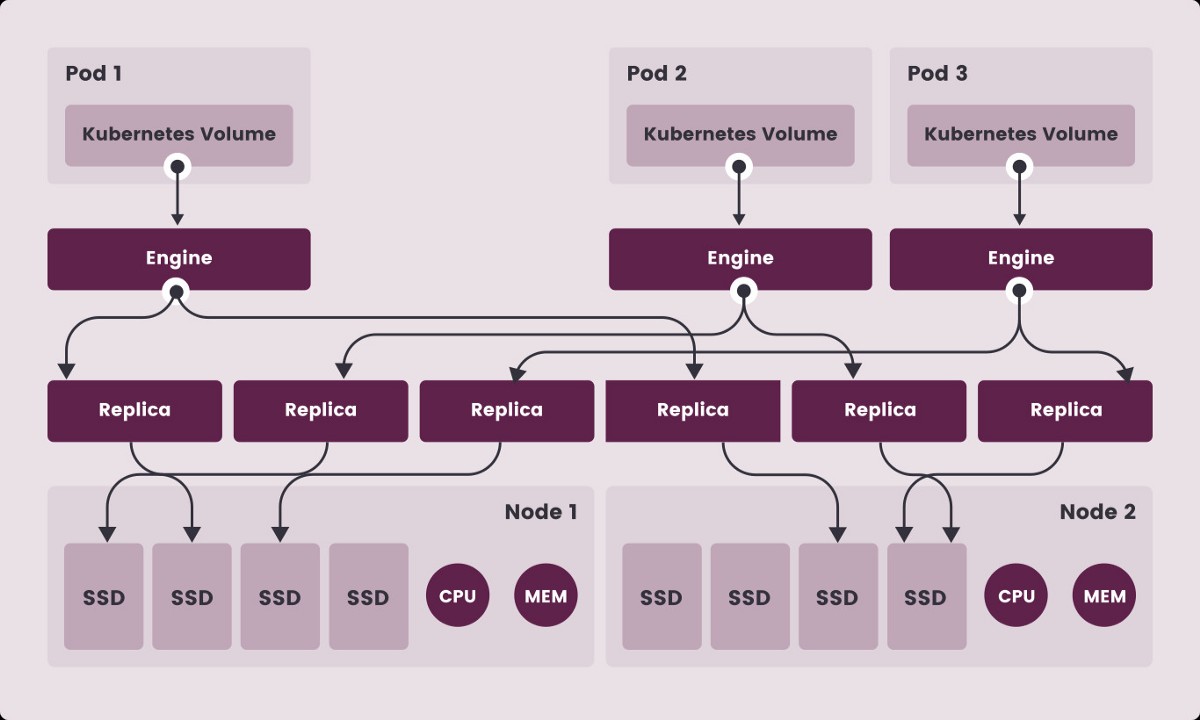
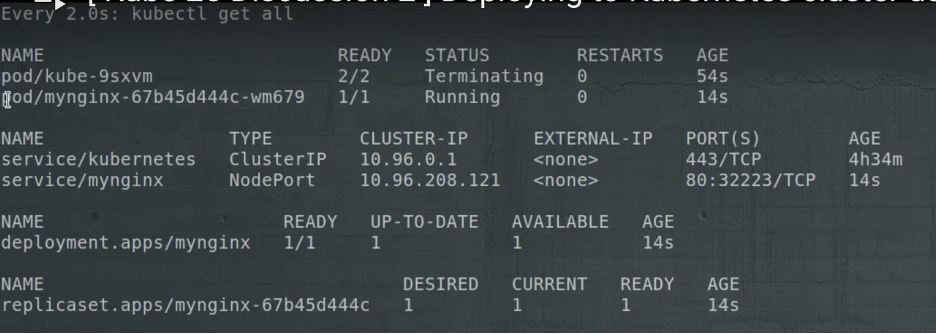
Case 1: Bạn đã cài đặt inject sidecar istio, virtualService, Gateway. Đùng cái owner của workload tự gỡ inject sidecar istio thì sẽ bị j?
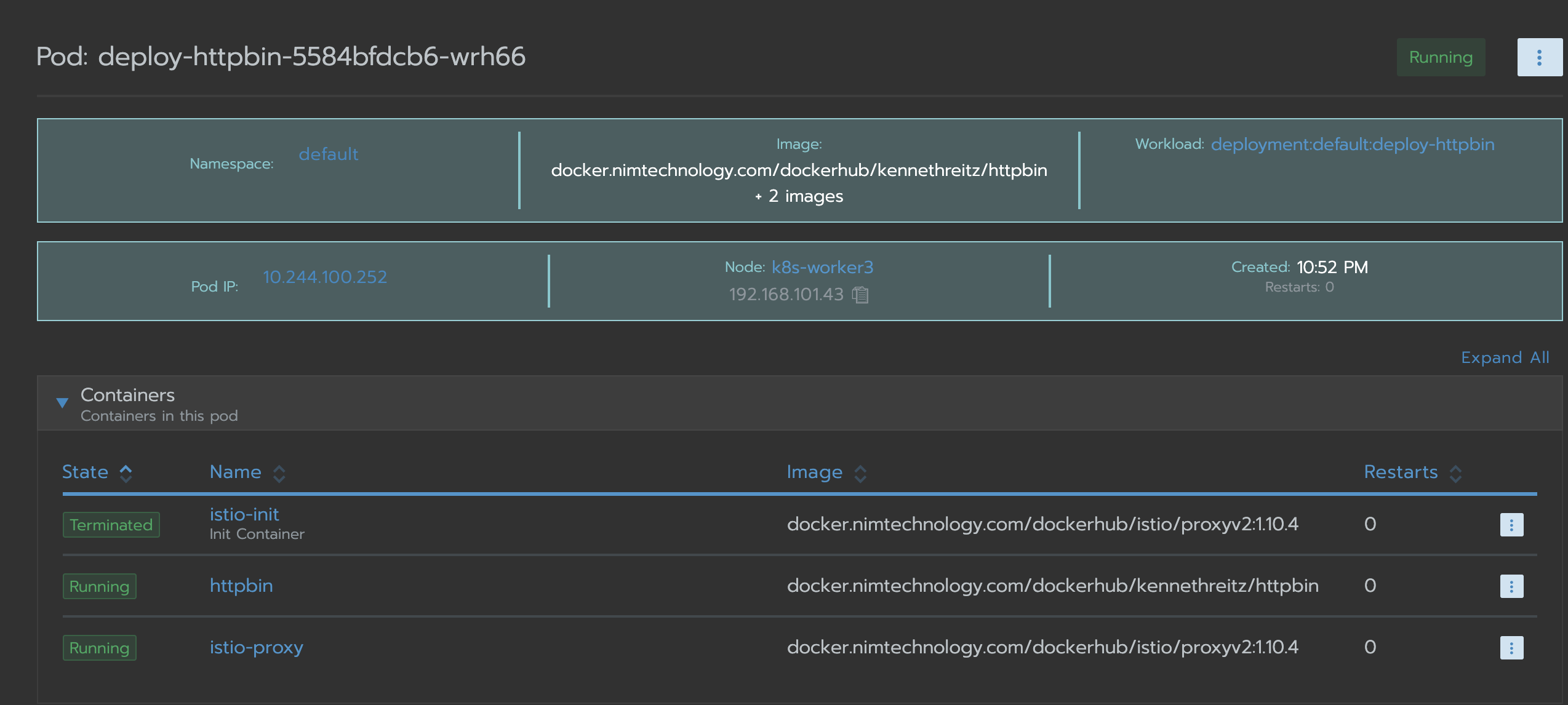
Bạn thấy app httpbin của mình đang có sidecar isito nhé
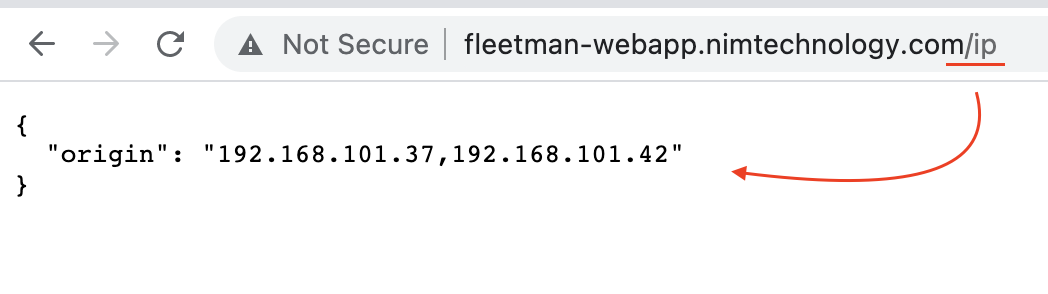
while true; do curl http://fleetman-webapp.nimtechnology.com/ip; echo; sleep 0.5; done
Mình curl vào link đó liên tục và quan sát kiali
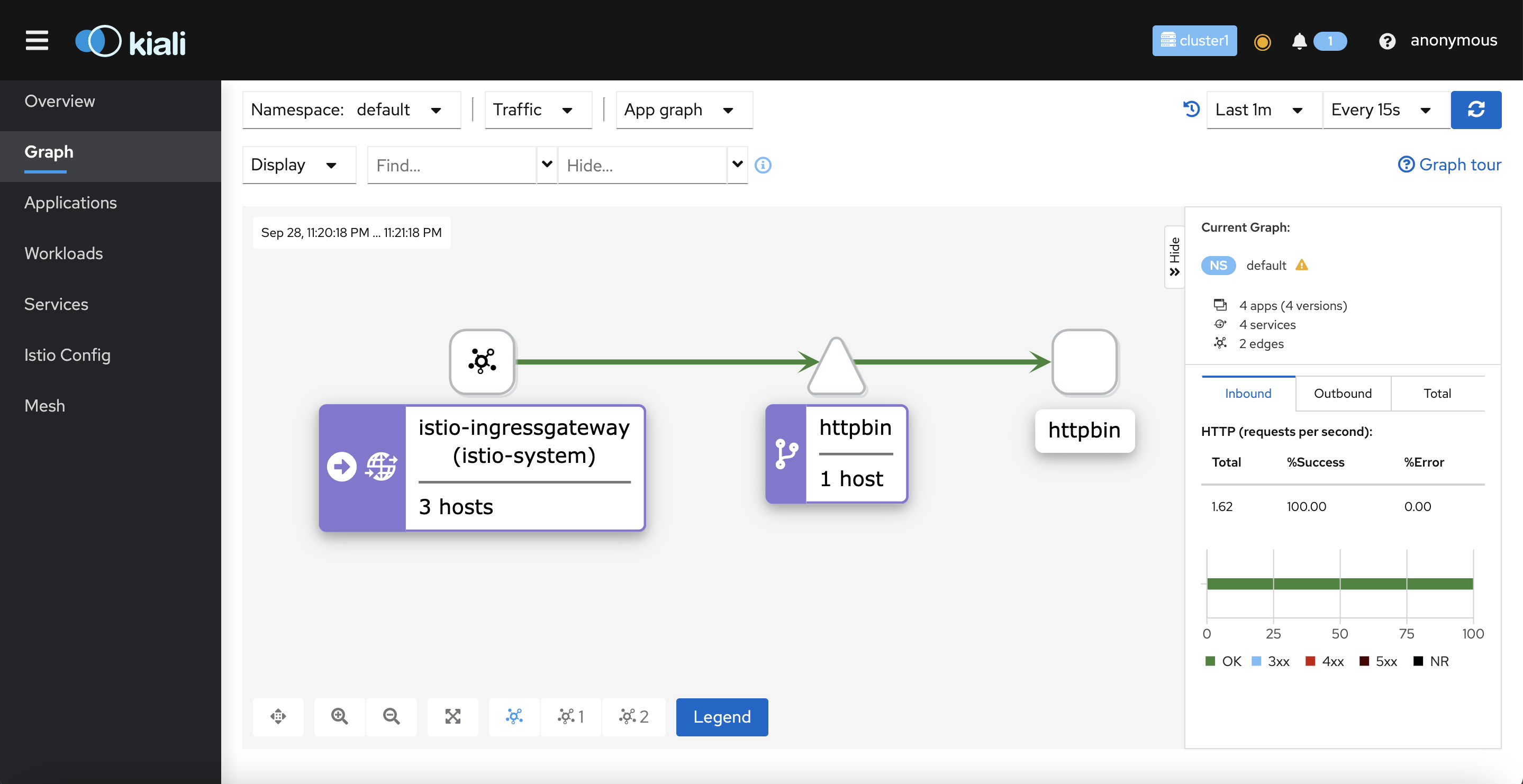
GIờ chán đơì gỡ inject ra thử hihi
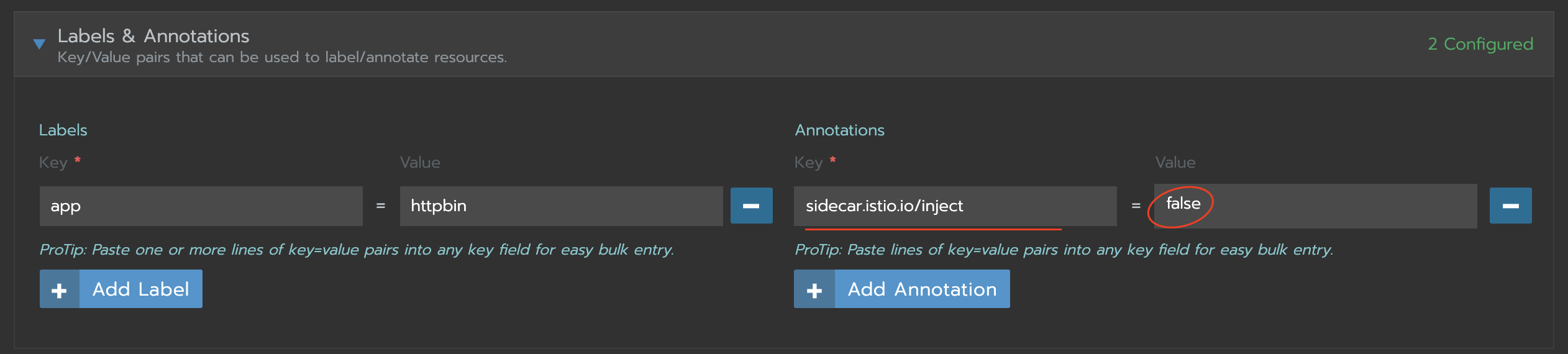

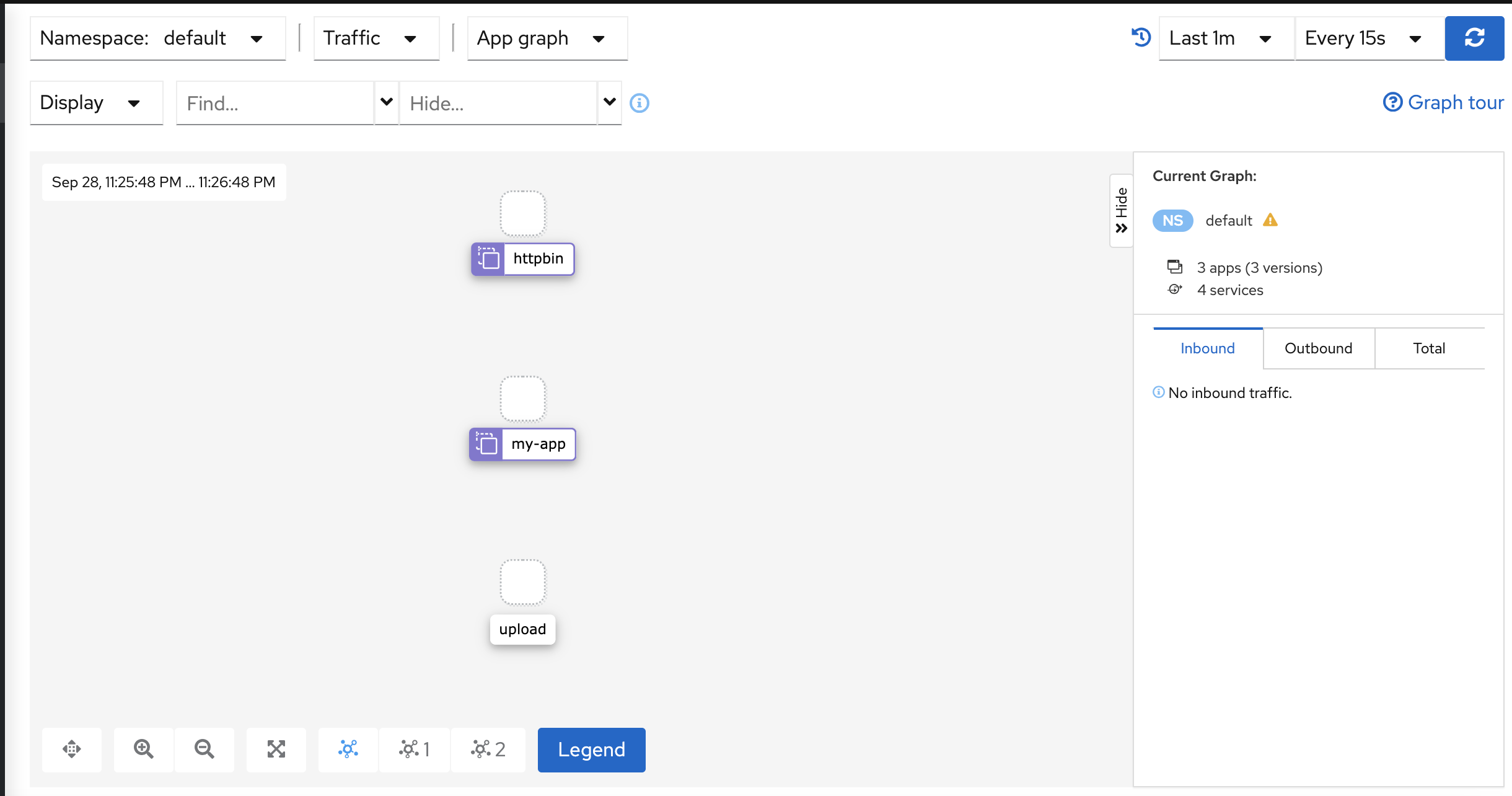

Lúc này thì virtualService, Gateway sẽ chạy như 1 ingress bình thường và đưa traffic xuống service nhé.
Đương nhiên là mấy canary, header, bala bala khả năng ko chạy được
Case 2: 2 virtualService, Gateway giống domain nhưng lại khác path.
trong đâu chúng ta nghĩ là:
– workload a sẽ truy cập bằng đường link: a.nimtechnology.com
– workload b sẽ truy cập bằng đường link: b.nimtechnology.com
Bạn thử sem mình nghịch j ko giống như case bên trên nhé
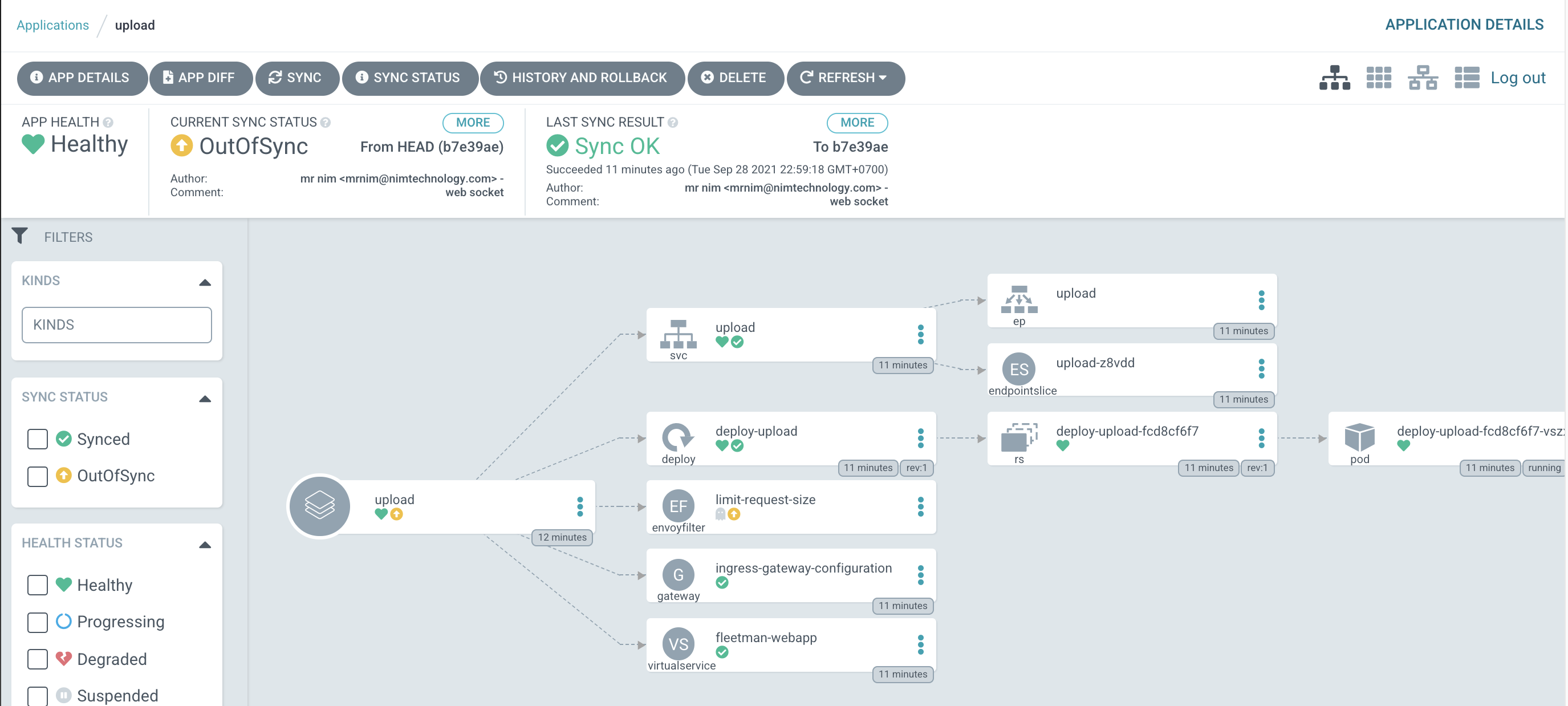
Mình tạo app trên là httpbin:

Mình cấu hình là với app này thì chỉ truy cập vào domain: fleetman-webapp.nimtechnology.com và path là: /ip
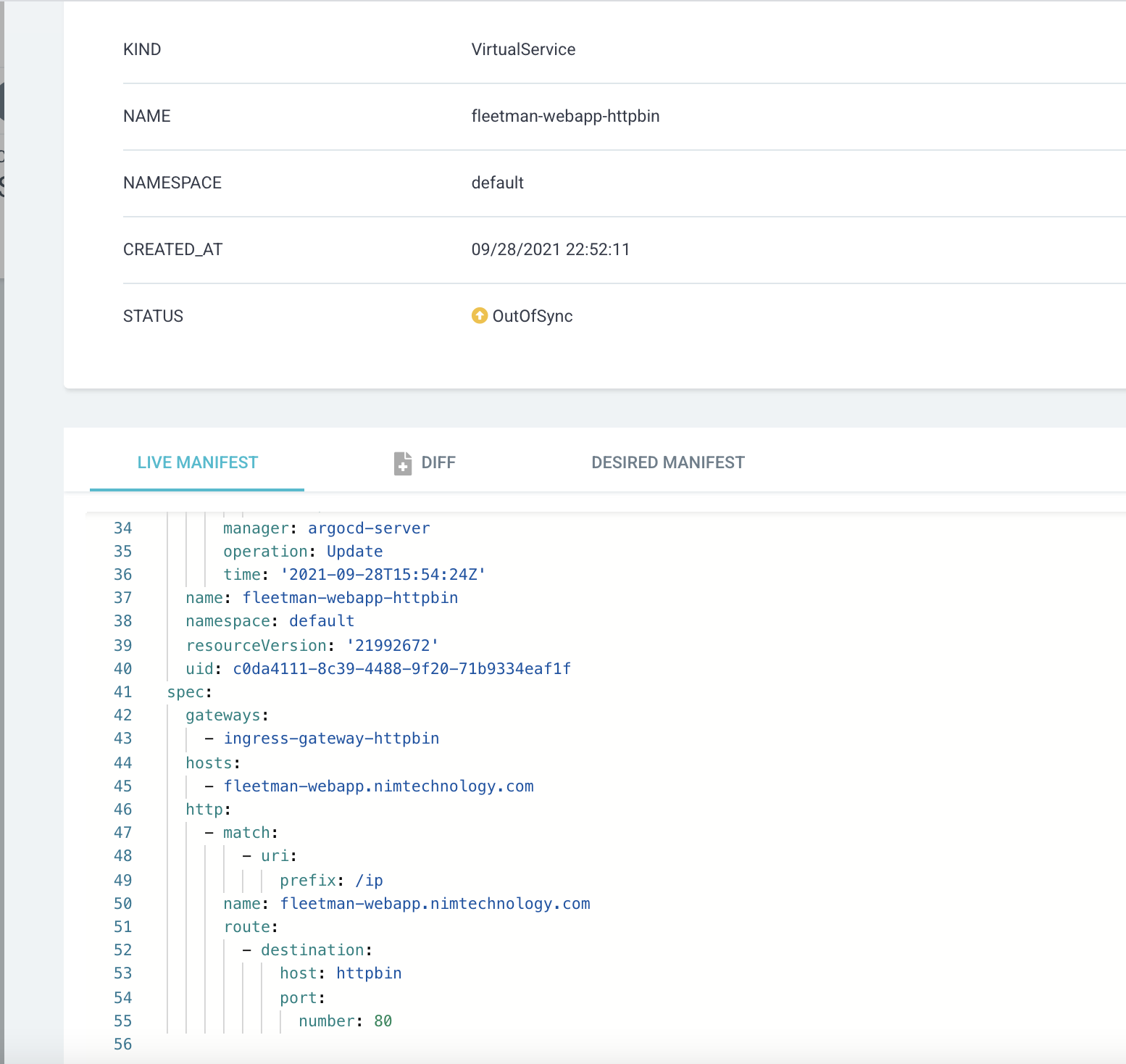
Kiểm tra truy cập:
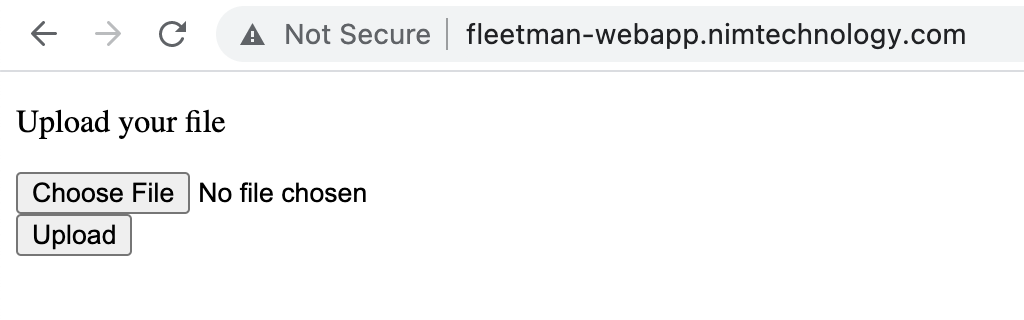
Mình tạo app để upload file
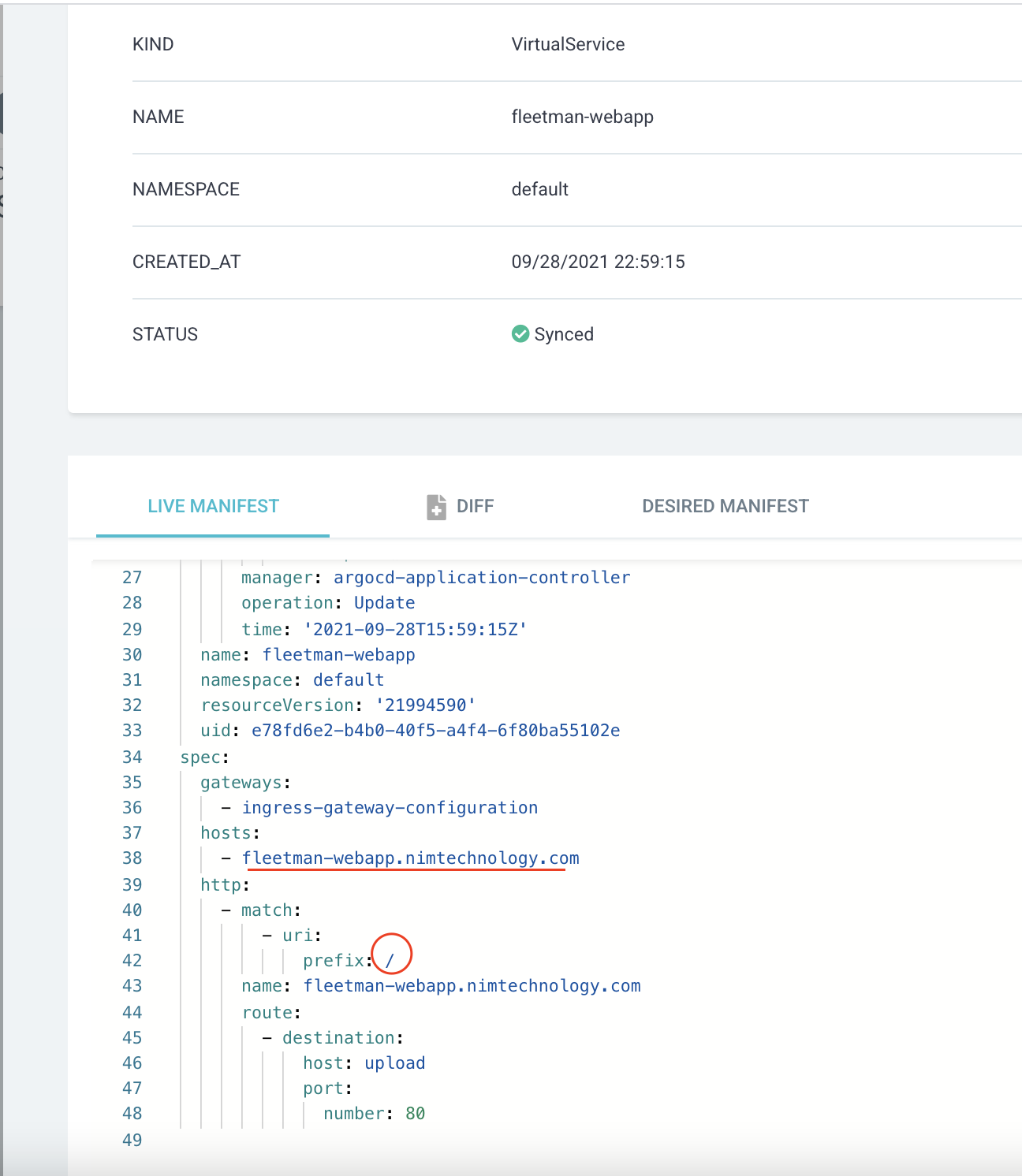
mà mình cho phép truy cập vào app này với domain: fleetman-webapp.nimtechnology.com và path là: /
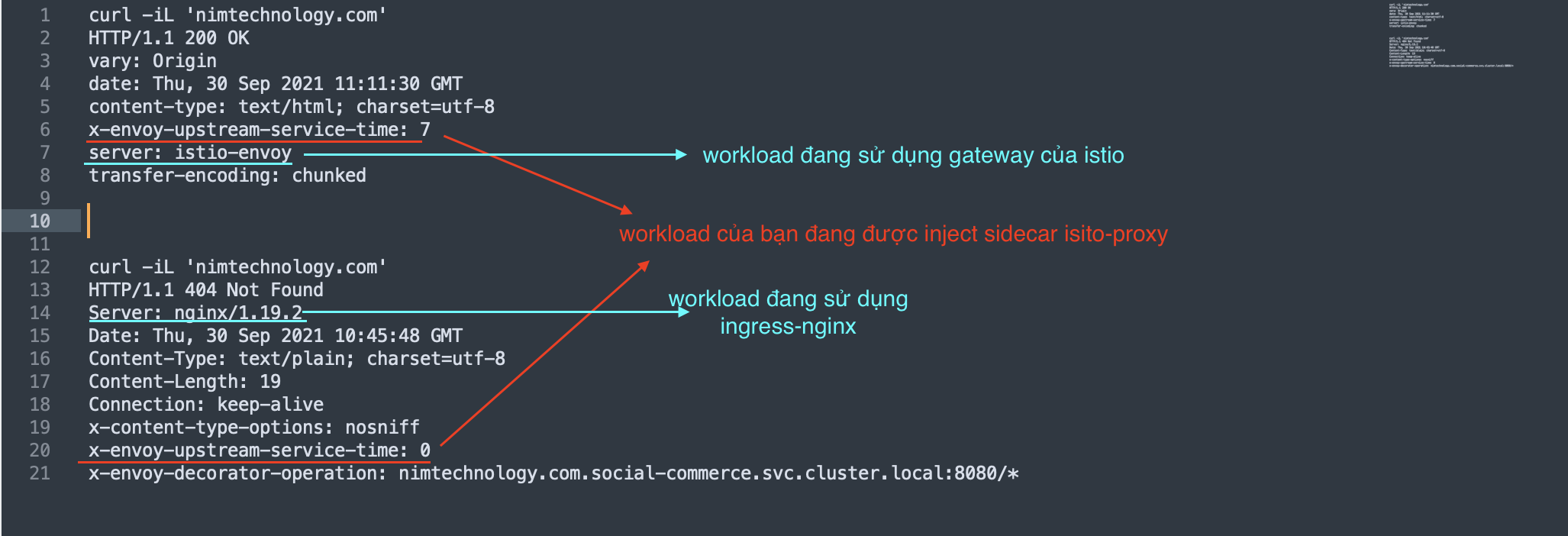
Case 3: Bạn đang phân vân workload có inject sidecar isito hay ko????, workload có đang sử dung ingress-nginx hay gateway của isito????
Dưới đây là cách:
Case 4: There are too few istiod pod to understand why istiod hang – update Sat 6 Nov 2021
Gần đây mình bắt gặp 1 số case như có 1 lỗi chung istio-proxy call về pilot bị lỗi và istio-proxy ko trong status ready
Đại loại các bạn sẽ hiểu istio-proxy sidecar ở workload nó sẽ gửi về pilot(istiod) một thứ là ADS.
Lúc này istiod nhận được thì new connection và push trả cho istio-proxy sidecar là XDS

Lúc đó bạn thấy istiod cluster primary ko có lỗi error j hết
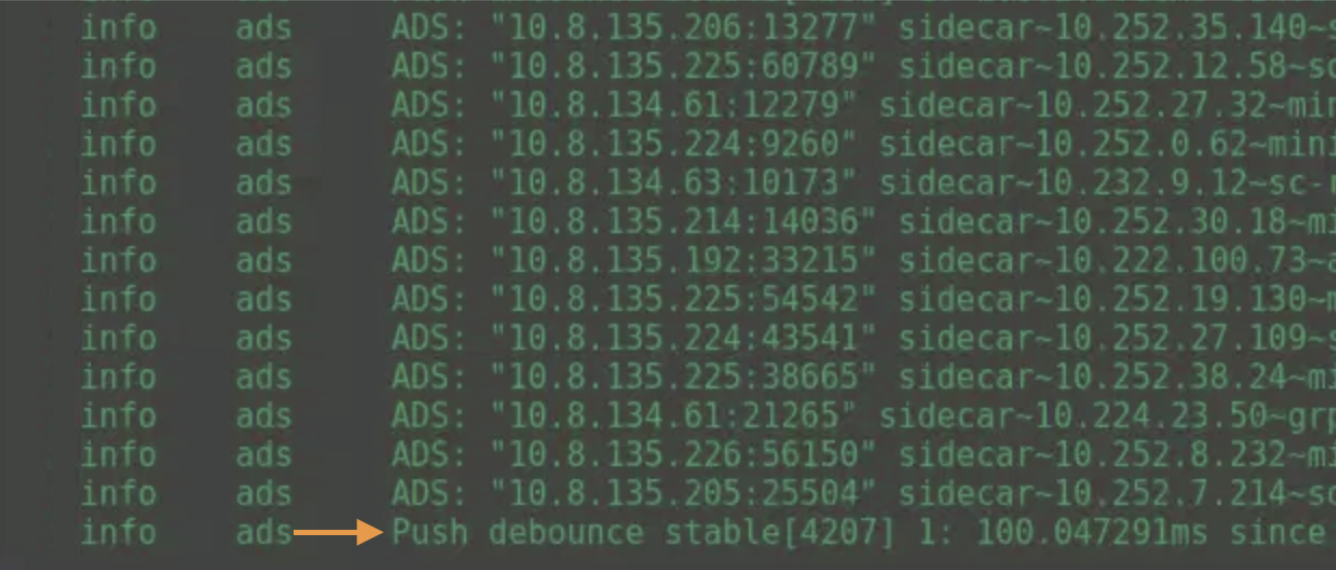
Hoặc là ở istiod ở cluster remote thì nó bị lỗi: unable to get node ….. not fount
sovle problem
Lúc đó thì ở istiod cần tăng scale hày replicate lên thì tạo ra pod istiod mới là hết lỗi và xoá các istiod có biêủ hiện lại.
Note
Mình có 2 điều muốn note lại.
1) Min scale HPA of istiod
ở cluster primary thì HPA min scale cho istiod nên là 5
ở cluster remote thì HPA min scale cho istiod nên là 2
2) request resource ram and cpu of Istiod shouldn’t too much
Có gặp 1 case là istiod bị treo ở tại thời điểm treo nhó cũng nắm kha khá connected.
Ví dụ để request cpu là 2
lúc đầu start istiod đang usage cpu là 500m, số lượng connected istio-proxy trên istiod tăng lên đột biến thế là cpu usage lên 1 ở đây thì nó bị treo và ko nhận connected nữa và cpu cũng ko tăng nữa.
HPA set cho CPU là 80%
Và thể istiod cũng ko scale thêm pod mới luôn thế là làm các connected trên dashboard rớt ầm ầm.
Case 5: container “istio-proxy” to inject to workload that is timeout.
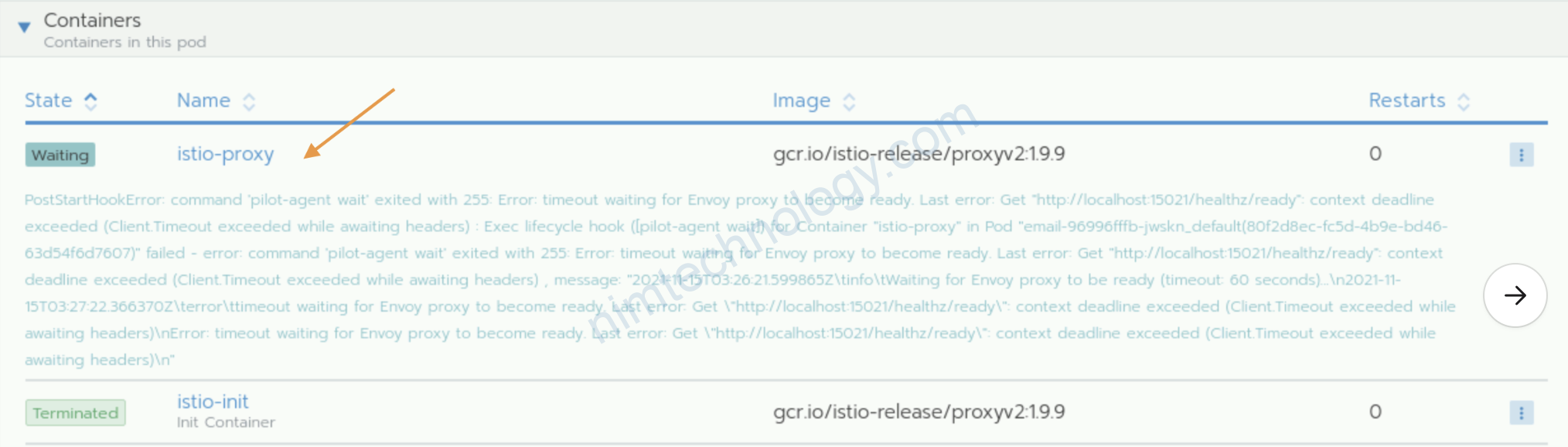

theo như một master debug:
có check log con istio-proxy thấy báo mấy lỗi liên quan tới access log tcp_proxy, nên e thử gỡ ra
rất tiếc là ko chụp lại được.
apiVersion: networking.istio.io/v1alpha3
kind: EnvoyFilter
metadata:
name: email
namespace: istio-system
spec:
configPatches:
- applyTo: NETWORK_FILTER
match:
listener:
filterChain:
filter:
name: envoy.filters.network.tcp_proxy
patch:
operation: MERGE
value:
typed_config:
'@type': type.googleapis.com/envoy.extensions.filters.network.http_connection_manager.v3.HttpConnectionManager
access_log:
- name: envoy.access_loggers.file
typed_config:
'@type': type.googleapis.com/envoy.extensions.access_loggers.file.v3.FileAccessLog
format: |
[%START_TIME%] "%REQ(:METHOD)% %REQ(X-ENVOY-ORIGINAL-PATH?:PATH)% %PROTOCOL%" %RESPONSE_CODE% %RESPONSE_FLAGS% "%DYNAMIC_METADATA(istio.mixer:status)%" "%UPSTREAM_TRANSPORT_FAILURE_REASON%" %BYTES_RECEIVED% %BYTES_SENT% %DURATION% %RESP(X-ENVOY-UPSTREAM-SERVICE-TIME)% "%REQ(X-FORWARDED-FOR)%" "%REQ(USER-AGENT)%" "%REQ(X-REQUEST-ID)%" "%REQ(:AUTHORITY)%" "%UPSTREAM_HOST%" %UPSTREAM_CLUSTER% %UPSTREAM_LOCAL_ADDRESS% %DOWNSTREAM_LOCAL_ADDRESS% %DOWNSTREAM_REMOTE_ADDRESS% %REQUESTED_SERVER_NAME% %ROUTE_NAME%
path: /dev/stdout
workloadSelector:
labels:
workload.user.cattle.io/workloadselector: deployment-default-email
Đang nghi vấn là istio 1.9.9 không hợp với name: envoy.filters.network.tcp_proxy