1) Overview.
Link tham khảo luôn:
https://kubernetes.io/docs/tasks/run-application/horizontal-pod-autoscale/
https://www.kloia.com/blog/advanced-hpa-in-kubernetes
https://github.com/kubernetes/enhancements/blob/master/keps/sig-autoscaling/853-configurable-hpa-scale-velocity/README.md#introducing–option
the “behavior” field with 1.18, v2beta2 API
apiVersion: autoscaling/v2beta2
kind: HorizontalPodAutoscaler
metadata:
labels:
app: istiod
istio.io/rev: default
release: istio
name: istiod
namespace: istio-system
spec:
maxReplicas: 15
metrics:
- resource:
name: cpu
targetAverageUtilization: 80
type: Resource
minReplicas: 2
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: istiod
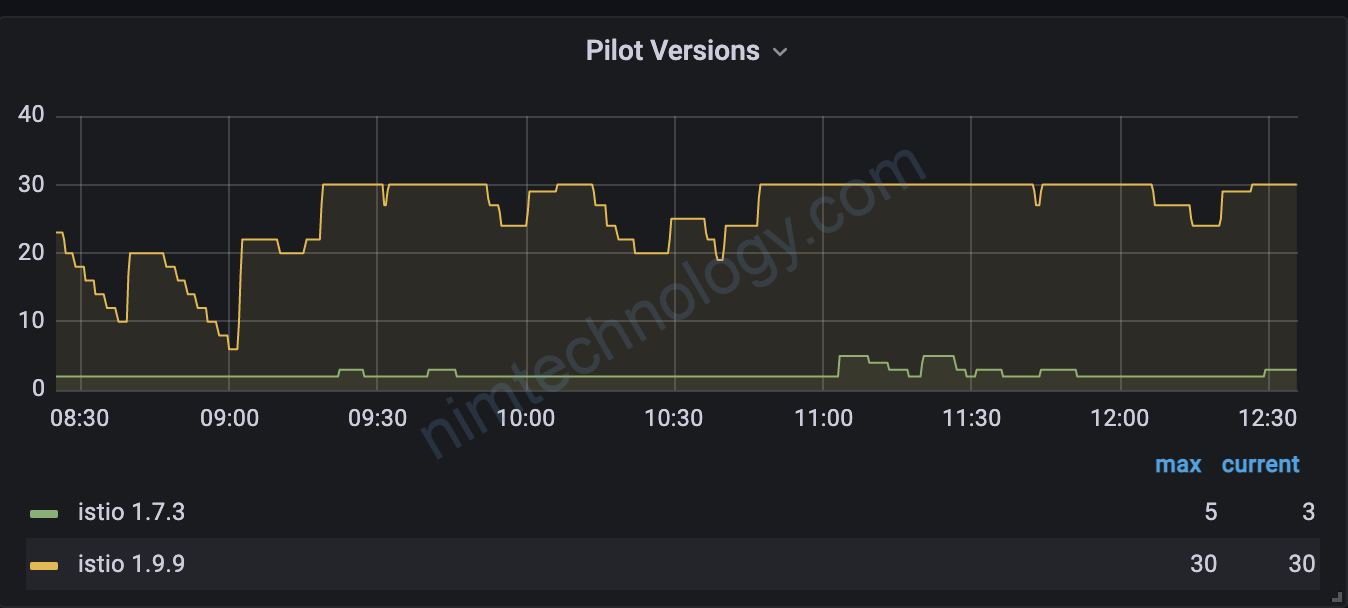
1.1) Scaled up and down erratically:
Thường thì HPA chúng ta sẽ đặt trên.
Tóm lại nếu cpu mà vượt quá 80% request thì scale cái ào lên 15 pod.
Nhưng với workload mà thay đổi liên tục CPU thì bạn sẽ thấy chart scale pod nó bị spike hay còn gọi là nhọn.
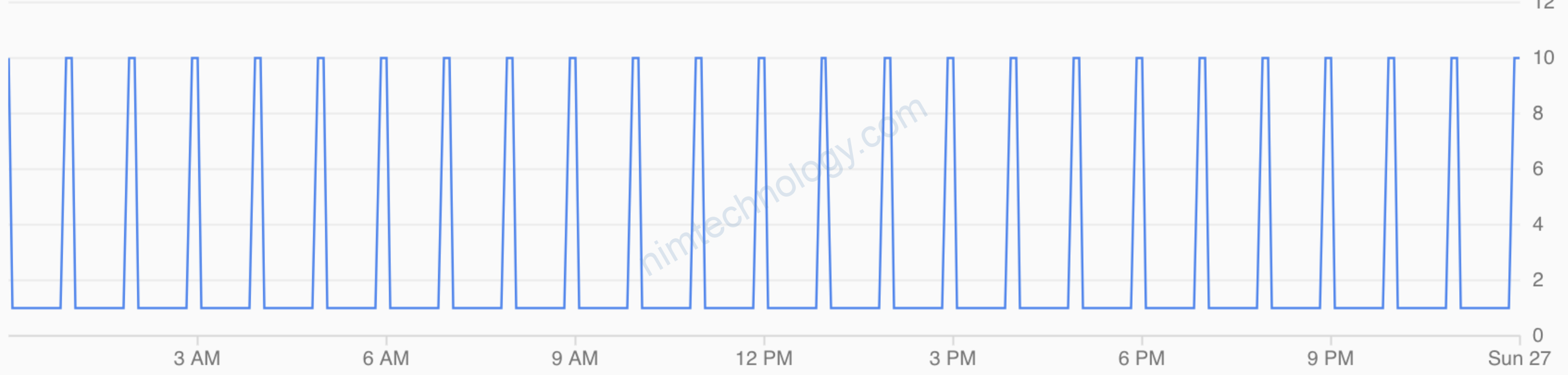
Mình gặp ở case. Istiod của mình đang 15 pod. lúc đó task trong mỗi istiod ít lại. cpu giảm xuống. Scale down.(1)
Vừa scale down thì số task tăng lên -> pod scale up không kịp thế là ít pod quá CPU tăng cao -> thế là lại scale up. -> (1)
Bạn sẽ bảo tăng min cao thêm tý. Các đó có vẻ cũng ok, nhưng ko triệt để.
Còn 1 vấn để nữa nếu bạn apply HPA thông qua việc giám sát CPU.
1.2) Lossless Detection:(Update Tue, 28 Dec, 2021)
Now let’s consider the example of a service with a spiky workload. The figure below contains 2 graphs. Ordered from top to bottom, they describe the following:
- Spiky nature of the workload
- Number of running pods
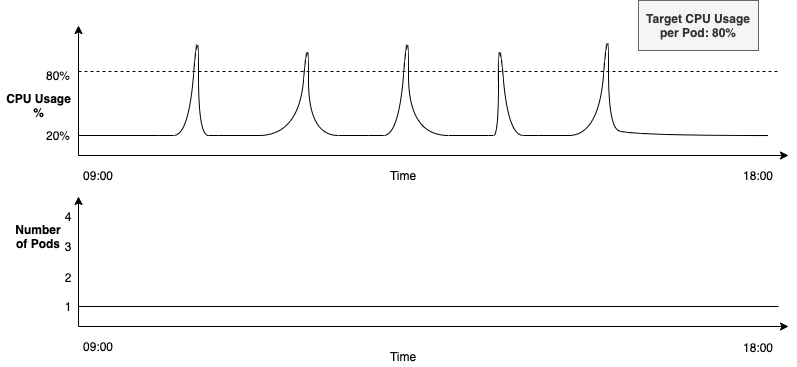
The service is configured to autoscale with the HPA. As can be seen in the top right corner of the above figure, it is configured to run at the desired CPU usage of 80%, with the minReplicas parameter set to 1.
With these points in mind, let’s look at what happens over time in this example.
- The workload remains low for a period of time, using < 20% CPU
- Then there is a sudden spike, taking the CPU usage > 80% for a brief few seconds
- The expectation is that when the CPU usage goes higher than 80%, then HPA should spin up a new pod to handle the increased workload
- But, as can be seen in the above figure, HPA doesn’t do this here
HPA can fail to detect workload spikes at times
1.3) Discover HPA’s scaling behavior feature
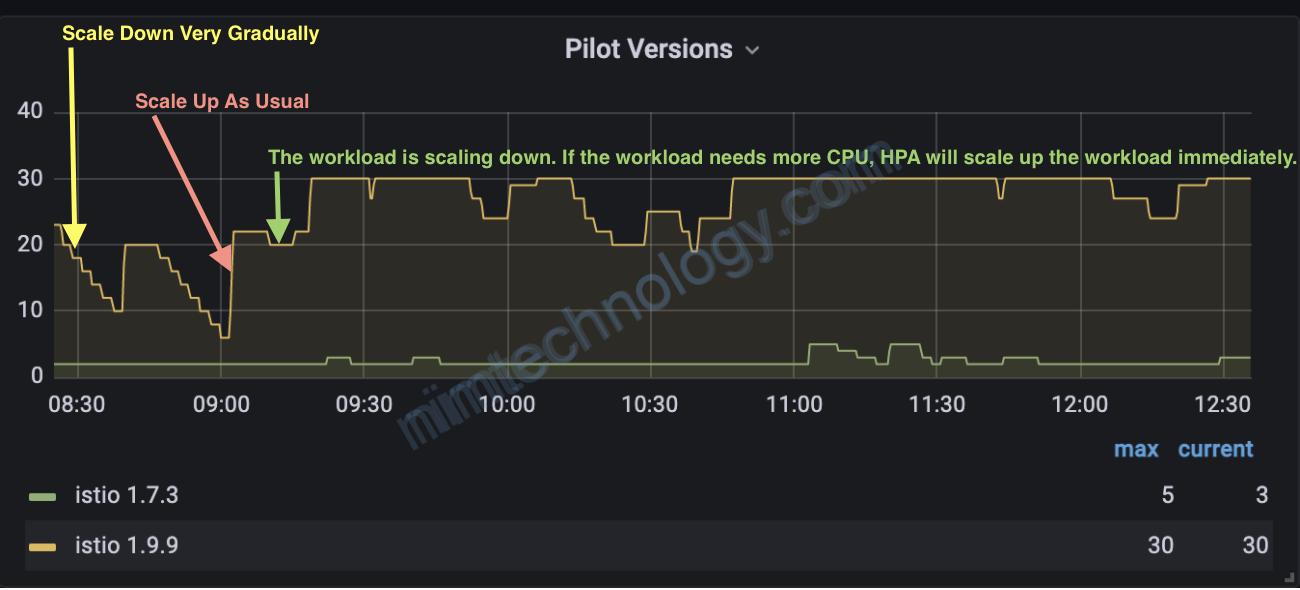
Ý tưởng chúng ta sẽ là scale up thì max tốc luôn, scale down giảm từ từ. Nghe ổn hơn đúng ko?
Vậy làm sao???
We’re using HPA’s scaling behavior feature, which controls how quickly our workloads should scale back down once the traffic load becomes less demanding. This is actually very important; it prevents your pods from being scaled up and down erratically, which is known as thrashing.
Trong HPA thì nó có 1 declared là behavior(hành vi)
apiVersion: autoscaling/v2beta2
kind: HorizontalPodAutoscaler
metadata:
labels:
app: istiod
istio.io/rev: default
release: istio
name: istiod
namespace: istio-system
spec:
maxReplicas: 15
metrics:
- resource:
name: cpu
targetAverageUtilization: 80
type: Resource
minReplicas: 2
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: istiod
behavior:
scaleDown:
policies:
- periodSeconds: 20
type: Pods
value: 3
- periodSeconds: 20
type: Percent
value: 10
selectPolicy: Max
stabilizationWindowSeconds: 10
Nếu bạn ko khai báo scaleUp thì nó sẽ Scale Up As Usual (scale như bình thường)
stabilizationWindowSeconds: mình gọi đây là khoảng thời gian thu thập dữ liệu
stabilizationWindowSeconds: This parameter controls how long the HPA waits before applying a scaling action after a change has been detected. For scale down default value is 300, maximum value is 3600 (one hour).
==> nếu bạn muốn scaledown chậm thì tăng cài này nhé
- While scaling down, we should pick the safest (largest) “desiredReplicas” number during last
stabilizationWindowSeconds. - While scaling up, we should pick the safest (smallest) “desiredReplicas” number during last
stabilizationWindowSeconds.
Tại thời điểm đó bạn đang có:
– CPU bạn xuống dưới 80%
– Bạn đang có 15 pod
thì nó có 1 tín hiểu scale down
stabilizationWindowSeconds: 10
ở 10s đầu tiên nó sẽ không làm gì và chỉ thu thập recommendations.
Trong 0s đến 9s:
Hiện tại bạn có 15 pod,
– Percent là 10% của 15 pod => 1.5 pod => làm tròn lên: 2 pod
– Pods là 3
selectPolicy: Max => recommendations = 15 – 3 = 12
Ví dụ cái list recommendations mà thư thập được trong 9s.
recommendations = [12, 11, 12]
Đến giây thứ 10
scale down nên HPA sẽ chọn số lớn nhất là 12
changes the number of replicas 15 -> 12
periodSeconds: 20
Thì nó sẽ chờ thêm 20s nữa nếu CPU vẫn thấp hơn 80% thì scale down
Đến giây thứ 30
Hết 20s nó sẽ thực hiện giảm pod xuống replicas xuống 12
2) Through development (update Thu, Dec 16th, 2021)
Hiện tại behavior trong autoscaling đang còn khá mới. Chúng ta sẽ sem thử đây có phải là 1 feature sáng lạng. Để kubernetes tiếp tục phái triển.
Theo như công bố: FEATURE STATE: Kubernetes v1.23 [stable]
https://kubernetes.io/docs/tasks/run-application/horizontal-pod-autoscale/#configurable-scaling-behavior
(the autoscaling/v2beta2 API version previously provided this ability as a beta feature)
If you use the v2 HorizontalPodAutoscaler API, you can use the behavior field (see the API reference) to configure separate scale-up and scale-down behaviors. You specify these behaviours by setting scaleUp and / or scaleDown under the behavior field.
You can specify a stabilization window that prevents flapping the replica count for a scaling target. Scaling policies also let you controls the rate of change of replicas while scaling.
Đọc qua vài trong trên thì thấy feature behavior sẽ stable trên Kubernetes v1.23 và apiVersion sẽ là autoscaling/v2
https://pkg.go.dev/k8s.io/api@v0.23.0/autoscaling/v2beta2
ở link trên thì anh em sẽ thấy behavior được add vào từ Versions in this module v 0.18.0

3) Practice.
Chúng tìm kiếm container nào để tăng CPU
Và mình chọn đại cái này.
docker pull petarmaric/docker.cpu-stress-test
Anh em cần cài prometheus-operator để monitor pod
Grafana thì anh/em sử dụng chart này
https://grafana.com/grafana/dashboards/10257
Đầu tiên mình test với HPA bình thường:
apiVersion: autoscaling/v2beta1
kind: HorizontalPodAutoscaler
metadata:
labels:
app.kubernetes.io/instance: cpu-stress
name: simple-hpa
namespace: sample
spec:
maxReplicas: 6
metrics:
- resource:
name: cpu
targetAverageUtilization: 50
type: Resource
minReplicas: 1
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: docker-cpustress
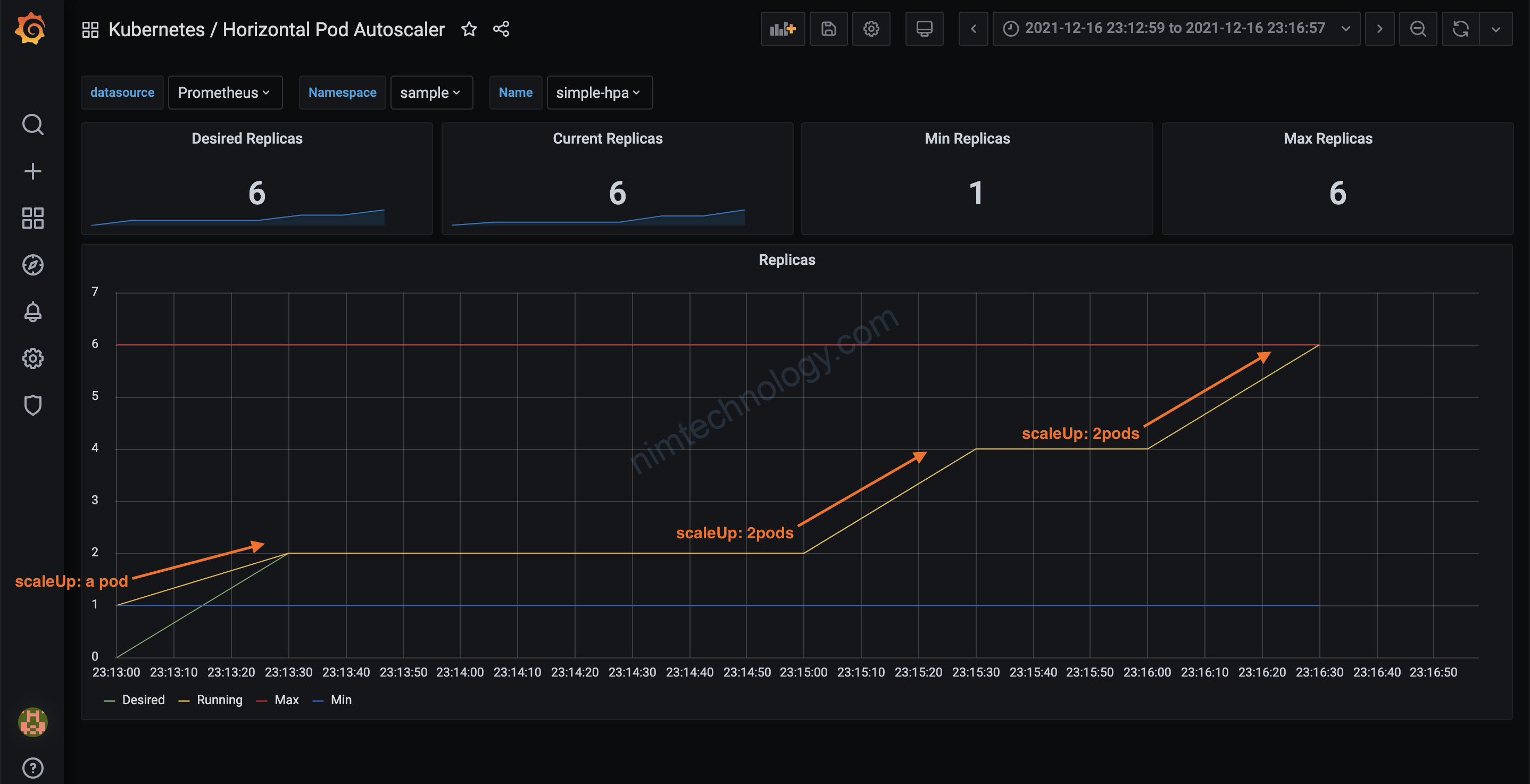
và mỗi lần tăng bao nhiêu pod?
HPA với behavior:
apiVersion: autoscaling/v2beta2
kind: HorizontalPodAutoscaler
metadata:
labels:
app.kubernetes.io/instance: cpu-stress
name: behavior-hpa
namespace: sample
spec:
behavior:
scaleUp:
policies:
- periodSeconds: 20
type: Pods
value: 1
- periodSeconds: 20
type: Percent
value: 10
selectPolicy: Max
stabilizationWindowSeconds: 10
maxReplicas: 6
metrics:
- resource:
name: cpu
target:
averageUtilization: 80
type: Utilization
type: Resource
minReplicas: 1
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: docker-cpustress
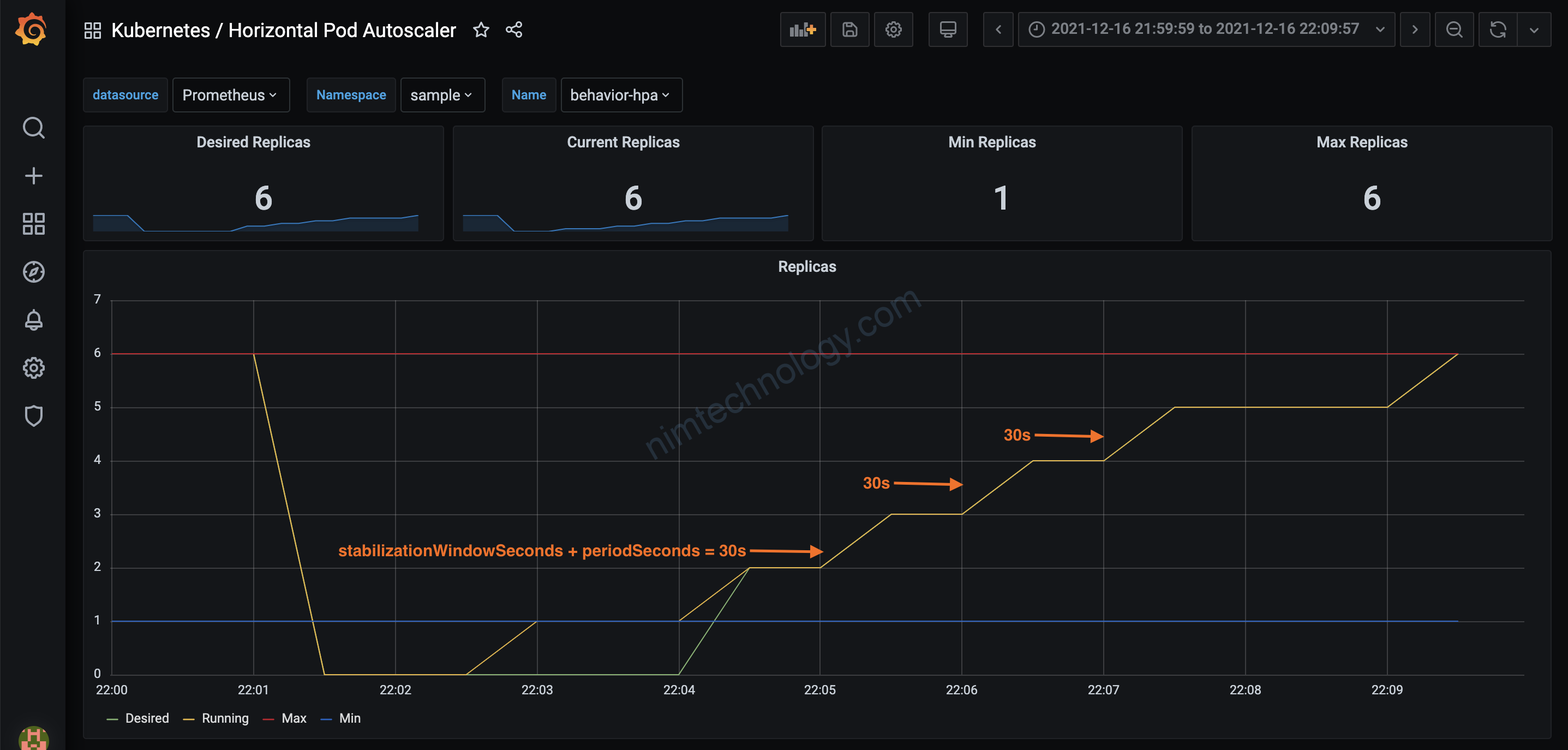
gồm 10s của stabilizationWindowSeconds và 20s periodSeconds.
Và mỗi lần mình chỉ muốn tăng 1 pod
Trong thực tế thì mình đã apply cho istiod và thấy khá hiệu quả.
vì các pod scale down ko quá nhanh.