In a fast-growing company, like Compass, things may become challenging for Cloud infrastructure teams. As serving more and more customers, many backend services scaled up in our Kubernetes clusters. Meanwhile, a variety of new backend services went online to satisfy new requirements.
Recently, a big challenge for our Cloud Engineering team in Compass is the shortage of IP addresses in some Kubernetes clusters which are managed by AWS EKS. I would like to share our experiences of troubleshooting, investigations, exploring solutions and mitigating the issues.
Problem Found
The problem was noticed first when some teams reported some transient failures during deployments in the staging environment. The logs can tell the reason of deployment failed.
Warning FailedCreatePodSandBox 17m kubelet, ip-10-0-0-100.ec2.internal Failed create pod sandbox: rpc error: code = Unknown desc = failed to set up sandbox container "a7c7ce835d262d7a3fd4ab94c66376e0266c03ba2fc39365cb108282f440b01a" network for pod "internal-backendserver-deployment-74f49769c5-nkdpn": networkPlugin cni failed to set up pod "internal-backendserver-deployment-74f49769c5-nkdpn_default" network: add cmd: failed to assign an IP address to container
Therefore, I started checking the VPC status of the Kubernetes cluster from AWS console and then found the available IP addresses for some private subnets reaching to 0.
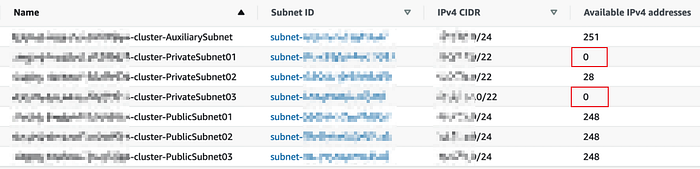
Our worker nodes in the Kubernetes cluster are only located in private subnets so two of there private subnets have 0 available IP addresses, while there are only 28 available IPs left on the other subnet.
According the CIDR on each Subnet (/22), there should have 1024 (²¹⁰) IP addresses for each and 3072 in total while there are about 1200 Pods running in that cluster actually.
Why did the IP addresses get exhausted?
AWS VPC CNI for Kubernetes
Since our Kubernetes clusters are AWS EKS clusters so it is important to introduce some concepts related to AWS VPC CNI plugins for understanding how Pod networking works.
ENI (Elastic Network Interface)
ENI could be considered as a network card for an EC2 instance (or a Kubenetes node). A single EC2 instance can have multiple ENIs attached, one primary plus several secondaries.
An ENI itself can hold multiple IP addresses. One is primary and the others are secondaries which could be assigned to Pods running on the EC2 instance.
When an ENI is created and attached to a EC2 node, it reserves a bunch of IPv4 addresses from the Subnet IP address pool.
AWS VPC CNI¹
CNI (Container Network Interface), a Cloud Native Computing Foundation project, consists of a specification and libraries for writing plugins to configure network interfaces in Linux containers, along with a number of supported plugins.
AWS VPC CNI is an implementation from Amazon to support Pod networking for Kubernetes clusters managed by EKS. It include 2 components, CNI plugin and a long-running node-Local IP Address Management (IPAM) daemon.
CNI Plugin
CNI Plugin, which will wire up host’s and pod’s network stack when called.
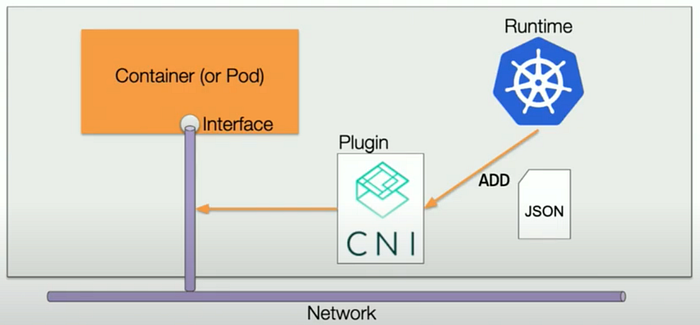
It executes the commands from Kubernetes (kubelet) to add/delete network interfaces (like ENIs) for Pods or containers on the host.
IPAM
For IPAM, it maintains a local warm-pool of available IP addresses on the host (node) and assigns an IP address to a Pod when it gets scheduled onto the node.
Here is the relationship between CNI plugin and L-IPAM.
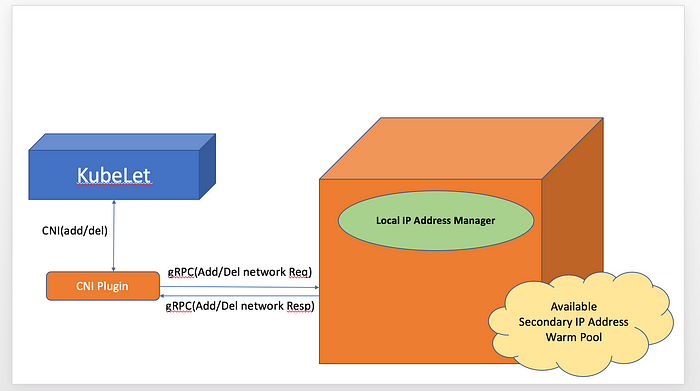
ENI Capacity
As mentioned above, an ENI is a virtual network interface which contains multiple secondary IP addresses.
For a single EC2 instance, there are two maximum numbers related to ENI:
- The maximum number of ENIs per EN2 instance.
- The maximum number of private IPv4 addresses per ENI.
Both maximum numbers are based on the EC2 instance type².
In our Kubernetes cluster, the worker nodes are type of m5.8xlarge, so the maximum number of ENIs is 8 while the maximum number of private IPv4 addresses per ENI is 30.
Per the formula¹ below, the maximum number of Pods a single node of m5.8xlarge can host is (8 * (30–1))+2=234 in theory.
(Number of ENIs × (Number of IP addresses per ENI - 1)) + 2
Maintenance of Warm Pool for Local IP Addresses
L-IPAM maintains the warm pool which contains all local available IP addresses and here is the logic.
Whenever the number of available IP addresses goes below a configured min threshold, L-IPAM will:
- create a new ENI and attach it to instance
- allocate all available IP addresses on this new ENI
- once these IP addresses become available on the instance (confirmed through instance’s metadata service), add these IP addresses to warm-pool.
Whenever the number of available IP addresses exceeds a configured max threshold, L-IPAM will pick an ENI where all of its secondary IP address are in warm-pool, detach the ENI interface and free it to EC2-VPC ENI pool.
Why IP Addresses Exhausted?
Once we understood the mechanism of how AWS VPC CNI manages the Pods and IP addresses on Kubernetes nodes, the reason of why IP addresses get exhausted by less number of Pods could be explained. In our case, 1200 Pods exhausted 3000+ IP addresses.
The short answer is IP address fragments on ENIs.
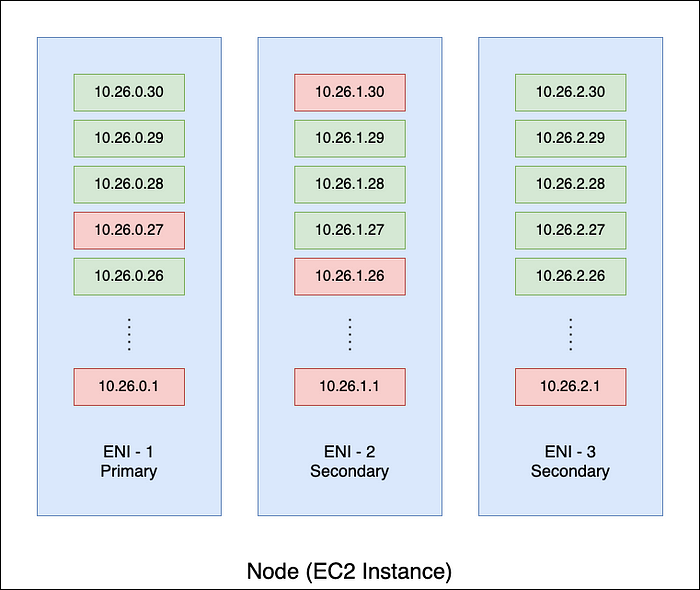
As illustrated in the figure above, IP addresses in use could be sparse on the ENIs but they hold them from being released.
Let’s assume an extreme case in our EKS Kubernetes cluster and the worker node is m5.8xlarge(128 GiB of Memory, 32 vCPUs, EBS only, 64-bit platform).
- Some pods are small with less requests/limits required while some others are big with more requests/limits required.
- Assume a node can host 100 small Pods or 10 big Pods.
- If a node hosts 100 small pods, it provides 100 IP addresses for the pods which needs at least 5 ENIs (100 // 29 + 1, 29 is used because the ENI itself also uses an IPv4 address so only 29 IP addresses available for Pods). So 147 (29 * 5 + 2) IP addresses are totally held by the node in the warm pool. It says, 47 IP addresses are wasted because they cannot be used by other nodes and no more Pods (either big or small) can be scheduled on this node.
- After some times, the 100 small Pods are refreshed out of the node gradually and in the meantime 10 big Pods are scheduled to the node running on all 5 ENIs so no ENIs get released. 147 IP addresses are still held. Therefore, 137 IP addresses are wasted in this case.
- We have about 1200 Pods in total running in the Kubernetes cluster. Let’s say 1000 small Pods and 200 big Pods, and then it needs at least 30 nodes (1000/100 + 200/10) to host all 1200 Pods in the cluster.
- So, in the worst case as assumed, 1200 Pods (1000 small Pods + 200 big Pods) hosted on 30 nodes can consume 4500 (150 * 30) IP addresses. It is far more than the number of total IP address in our 3 Subnets (which is about 3000 IP address mentioned above).
Even though it is the worst case where the Pod distribution is extremely unbalanced, it is also possible to running into the situation of exhausting IP addresses in an EKS Kubernetes cluster when the number of services increases gradually.
This is because the ENI cannot be released even though only one of the IP addresses on it is in use. The other IP addresses on that ENI are not in use and thus cannot be returned to the subnet IP pool for be allocated to other nodes.
On a single node, a small amount of IP addresses in use might be distributed on multiple ENIs, which looks like IP address fragments. Looking back the case of 10 big Pods holding 5 ENIs, there are 137 addresses wasted. If those 10 Pods hold the IP addresses on the same ENI, then it would hold 2 ENIs (since there should be a standby ENI by default). That says, 90 IP addresses are released and can be used by other nodes.
Potential Solutions
After the root cause was clear, I explored multiple solutions with pros and cons.
Add Another Subnet With Extra CIDR — Not Applied
The first question came to my mind is if the current CIDR block can be replaced with a large one for the EKS Kubernetes cluster. Unfortunately, the answer is No that AWS doesn’t support that.
AWS provides another solution, using a secondary CIDR for the EKS. It keeps the current CIDR and subnets but adding a new subnet with a new CIDR³.
Pros:
- It extends the available IP addresses for existing EKS clusters like patching.
Cons:
- Too many manual steps which is the biggest concern. In Cloud Engineering team, all Kubernetes clusters are maintained by our tooling with config files so any changes should be applied by tooling instead of running AWS commands or
kubectlmanually. Then, it would cost a lot effort to update tools and also a huge effort for testing it. - It requires draining the nodes in the original subnets to move the Pods to the nodes in the newly created subnet.
Use Smaller EC2 Instances — Not Applied
More powerful EC2 instances are, more IPs and ENIs the EC2 instance can hold.
For example,
An m5.2xlarge EC2 node can host up to 4 ENIs and each ENI on it can hold 15 IP addresses.
An m5.8xlarge EC2 node can host up to 8 ENIs and each ENI on it can hold 30 IP addresses.
Pros:
- Limits the number of Pods running on a single node which also limits the waste of IP addresses.
Cons:
- The number of nodes increases when hosting same number of Pods because the smaller EC2 instances are less powerful. It might impact your AWS bills a little, since less powerful means lower price for a single node but the number of nodes increases.
- Potential cost of Datadog as a monitoring system increases. It is because Datadog charges us based on the number of instances, so more nodes means more cost.
Replace AWS VPC CNI with Calico — Not Applied in Short Term
Since Kubernetes CNI is an interface, Calico is another implementation which is also supported by AWS EKS⁴.
Pros:
- Calico maintains a global IP address pool in the Kubernetes cluster for being assigned to Pods, so no IP addresses is unused or wasted at all.
Cons:
- Lose most AWS supports for EKS network issues since they strongly recommend that you either obtain commercial support, or have the in-house expertise to troubleshoot.
Draining Nodes With Wasted IP Addresses — Applied
The cause of the IP address being exhausted is the unbalanced distribution of IP addresses on ENIs. Then, how about forcing the Pods re-balancing to other nodes with spare available IP addresses by draining a node?
Pros:
- It trigger Kubernetes to relocate the pods to other nodes with available resources and IP addresses.
- It releases ENIs and the IP addresses allocated on them from the drained node immediately.
- Easy to execute.
Cons:
- Be careful to choose proper nodes to drain.
- In order to be able to drain a node, there should have some available IP addresses in your Subnets. Because the Pods evicted from the drained node might not find a proper node to be scheduled on, so they would be waiting for a new node created and joining into the cluster. If no IP addresses available in all Subnets, the new created node cannot host any Pods until the draining completes and releases IP addresses to the Subnet IP address pools.
We used this solution some times to mitigate the IP address shortage issues in the Kubernetes cluster. It is helpful but not a long term solution so we only use it for mitigating the issue first.
Customize WARM_IP_TARGET — Applied
All the situations and assumptions introduced above are based on default settings for the CNI configuration variables, WARM_IP_TARGET and MINIMUM_IP_TARGET⁵, which are not set by default. So when a new ENI added to a node, it will be filled to its maximum capacity of IP addresses and most of them could be not used or wasted for a long time.
The good news is, we can set a smaller value of WARM_IP_TARGET to decease the number of reserving IP addresses on the ENIs that avoid wasting more IP addresses.
Pros:
- Pretty a small change to existing Kubernetes clusters.
- Take effect immediately and release some IP addresses from existing ENIs.
Cons:
- The biggest concern is to increase the number of AWS EC2 API calls when attaching and detaching IP addresses. So, it needs to choose a proper number very carefully⁵.
- It needs to restart the
aws-nodepod on each node in the cluster.
We applied this solution on our Kubernetes cluster to set the value of WARM_IP_TARGET to 15 which is half of the maximum capacity of the ENI on a m5.8xlarge EC2 instance. However, this number is not finalized yet and we are still tuning it.
After the change, there are about 1000 IP addresses released so the issue was mitigated immediately.
Since we changed the default settings of AWS VPN CNI, it is important for us to monitor the status of it. Fortunately, the Prometheus service monitor is ready for collecting AWS CNI metrics in the Kubernetes cluster and showing in the Grafana dashboards.
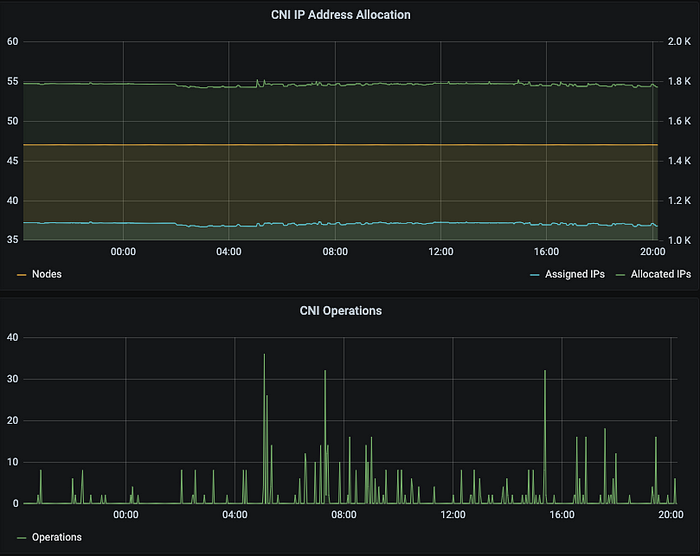
There are several metrics we are monitoring:
- IP Address Allocation, it monitors how many IP addresses allocated (held by ENIs) and assigned (used by Pods) in total. It tells how many unused IP addresses reserved by ENIs and some of them can be used in future while some others cannot.
- CNI Operations, it tells about the operation count from AWS CNI plugin because the lower value of
WARM_IP_TARGETincreases the EC2 API calls which has a limit in AWS account level.
Create Another Cluster With A Larger CIDR Block — Applied
Another solution is to create a new EKS Kubernetes cluster with a large CIDR block and then move some of services from the old cluster to the new one.
Pros:
- The new cluster has more IP addresses available so it can hold more apps.
Cons:
- Need effort to migrate some apps to the new cluster for both Cloud Engineering team and feature teams.
- It might involve some networking setting changes to route the traffic to the new cluster as well.
This solution would be applied sooner or later since the number of backend services keeps increasing in Compass so we prepared for it ahead. For new apps, we put them to this new cluster directly while moving some apps from the old cluster to release some IP addresses.
References
- AWS VPC CNI: Pod networking (CNI) — Amazon EKS
- The list of IP addresses per network interface per instance type: Elastic network interfaces — Amazon Elastic Compute Cloud
- Optimize IP addresses usage by pods in your Amazon EKS cluster | Containers
- Installing Calico on Amazon EKS — Amazon EKS
- amazon-vpc-cni-k8s/eni-and-ip-target.md at master · aws/amazon-vpc-cni-k8s (github.com)